[Java] ConcurrentHashMap
ConcurrentHashMap의 내부구조

ConcurrentHashMap이란?
ConcurrentHashMap은 Java 1.5 버전에서 HashTable의 대안으로 소개 되었다. Java 1.5 버전 이전에는 concurrent하고 multi-threaded 를 고려한 map을 구현하려면 HashTable 또는 synchronized map을 사용해야 했다. 왜냐하면 HashMap은 thread-safe 하지 않았기 때문이다.
ConcurrentHashMap은 concurrent multi-threaded 환경에서 안정적으로 동작하고 HashTable과 synchronized map 보다 더 나은 성능을 가지고 있다. 그 이유는, ConcurrentHashMap은 map의 일부에만 lock을 거는데 반해, 앞의 두 가지는 map 전체에 lock을 걸기 때문이다. map 전체에 lock을 거는 것은 성능 오버헤드를 발생시킨다. 하나의 쓰레드가 락을 유지하는 동안, 다른 모든 쓰레드는 컬렉션을 사용할 수 없다.
oracle docs에 따르면,
검색의 전체 동시성과 업데이트에 대한 높은 기대 동시성을 지원하는 해시 테이블입니다. 이 클래스는 Hashtable과 동일한 기능 사양을 준수하며, 각 Hashtable 방법에 해당하는 메소드 버전을 포함한다. 그러나 모든 작업이 스레드 안전함에도 불구하고 검색 작업은 잠금을 수반하지 않으며 모든 액세스를 방지하는 방식으로 전체 테이블을 잠글 수 있는 어떠한 지원도 없습니다. 이 클래스는 동기화 세부 정보가 아닌 스레드 안전성에 의존하는 프로그램에서 해시 테이블과 완전히 상호 운용 가능합니다.
ConcurrentHashMap putVall 메소드를 보면
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}ConcurrentHashMap은 Hashtable과는 다르게 put() 메서드에 synchronized 키워드가 붙어있지 않다. 위의 코드에서 중간쯤을 보면 동일 Entry(아래 코드에서는 Node)에 추가 될 경우 해당 Entry에 대해서 synchronized를 적용한 것을 확인할 수 있다. 즉, Entry 배열 아이템 별로 동기화 처리를 하고 있는 것이다. 이런 방식은 MultiThread 환경에서 성능을 크게 향상시킨다.
ConcurrentHashMap concurrencyLevel, loadFactor

기본값으로는 Capacity 는 16, MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8, loadFactor는 0.75, concurrencyLevel은 16으로 정해져 있다. 또 ConcurrentHashMap은 키 값에 null을 허용하지 않는다.
여기서 concurrencyLevel = 16을 주의깊게 보자.
ConcurrentHashMap은 기본적으로 16개의 세그먼트로 나뉘어져 있고, 각 세그먼트별로 다른 lock으로 동기화 되도록 만들었다. 세밀한 locking 방법을 적용시켜 오버헤드를 줄였다
ConcurrentHashMap의 내부구조를 깠을때, 4번째 생성자는 아래와 같다. concurrencyLevel을 이용하여 세그먼트 갯수를 정할 수 있다. 여기서 세그먼트 갯수는 분리된 세그먼트당 락을 갖도록 하기 때문데 멀티 쓰레드에서 전체적링 락킹 방법보다 훨씬 효율적이고 뛰어난 성능을 보여준다.
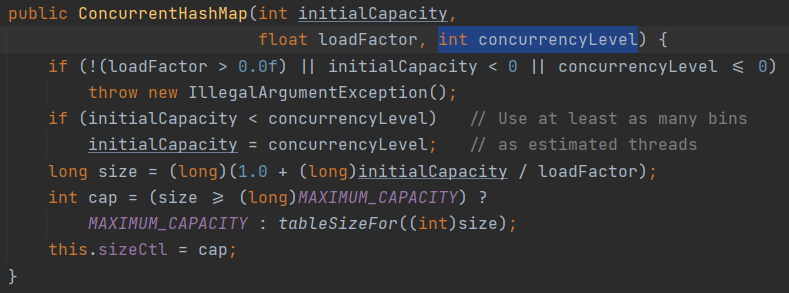
loadFactor
HashMap 에서는 loadFactor따라서 table 이 resize 되는 시점이 결정되지만, ConcurrentHashMap 에서는 이 인자 값과 상관 없이 0.75f로 동작한다. 예를 들어, 초기 테이블 크기가 16 이면 entry 수가 12개가 될 때 해시테이블 사이즈를 16에서 32로 증가시킨다.
ConcurrentHashMap의 리사이징

HashMap 에서의 리사이징은 단순히 resize() 함수를 통해 새로운 배열(newTab)을 만들어 copy 하는 방식이였지만,
ConcurrentHashMap 에서는 기존 배열(table)에 새로운 배열(nextTable) 로 버킷을 하나씩 전송(transfer) 한다. 이 과정에서 다른 스레드가 버킷 전송에 참여할 수도 있다. 전송이 모두 끝나면 크기가 2배인 nextTable 이 새로운 배열이 된다.
변수 sizeCtl 과 resizeStamp 메서드를 통해 resizing 과정이 중복으로 일어나지 않도록 방지한다.
정리
MultiThread 환경에서 동기화 처리가 필요하다면 ConcurrentHashMap을 사용하는 것이 안정적이다. 동기화가 필요하지 않은 경우라면 그냥 HashMap을 사용하자. Hashtable은 Thread-Safe 하긴 하나 느리다는 단점이 있다.