
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 쿠버네티스
- 토비의 스프링 정리
- Java
- 보조스트림
- GC
- IntellJ
- 자바 ORM 표준 JPA 프로그래밍
- K8s
- spring
- 스트림
- SpringBoot
- Real MySQL
- Stream
- mysql
- redis
- 스프링
- 이스티오
- MSA
- jvm
- Stack
- gradle
- Collection
- Kotlin
- 백준
- thread
- 자바
- 토비의 스프링
- OS
- JPA
- list
- Today
- Total
인생을 코딩하다.
[DB] Redis와 memcached 비교 본문

프로젝트를 scale out 방식으로 확장할 계획을 하면서 그에 따른 session의 정합성에 관한 이슈가 생겼습니다.
별도의 독립적인 session 저장소로 세션의 정합성 문제를 해결하기 위해서는 대표적인 redis와 memcached 데이터 베이스를 고려해볼 수 있습니다.
Amazon ElastiCache는 Memcached 및 Redis 캐시 엔진을 지원합니다. 각 엔진에는 몇 가지 장점이 있습니다. 이 항목의 정보를 활용하면 요구 사항에 가장 잘 맞는 엔진과 버전을 선택하는 데 도움이 됩니다.
Memcached와 Redis 엔진은 둘 다 인 메모리 키-값 저장소입니다. NoSql 데이터베이스라고도 할 수 있죠. 그러나 실제로 상당한 차이점이 있습니다.
session의 정합성 이슈를 해결하기 위해서 두 개의 엔진중 어떤 것을 선택하는게 좋을까요?
다음과 같은 경우 Memcached를 선택합니다.
- 상대적으로 작고 정적인 데이터를 캐싱하는 경우
- 여러 코어 또는 스레드가 있는 멀티 스레드의 경우
- 메모리 관리가 redis만큼 정교하지는 않지만, 메타 데이터에 대한 메모리 리소스를 비교적 적게 소비하여 간단한 사용에 적합하다.
- 쉽게 확장할 수 있지만 해싱 사용 여부에 따라 캐시된 데이터의 일부 또는 전부를 잃는다.
그럼 Redis는 어떤 경우에 선택할까요?
- 문자열, 해시, 목록, 세트, 정렬된 세트 및 비트맵과 같은 복잡한 데이터 유형이 필요한 경우
- 인 메모리 데이터 세트를 정렬하거나 순위를 지정해야 하는 경우
- 키 저장소의 속성을 원할 경우
- 읽기 집약적 애플리케이션을 위해 기본 항목에서 하나 이상의 읽기 전용 복제본으로 데이터를 복제해야 하는 경우
- 기본 노드가 실패할 때 자동 장애 조치가 필요한 경우
- 서버에 대한 이벤트를 클라이언트에 알리기 위해 게시 및 구독(게시/구독) 기능이 필요한 경우
- 백업 및 복원 기능이 필요한 경우
- 여러 데이터베이스를 지원해야 하는 경우
대표적인 경우만 적어보았지만, 이 외에도 여기을 보시면 더욱 많은 경우를 확인하실 수 있습니다.
간단하게 차이점을 표로 정리해보겠습니다.
| Redis | Memcached | |
| 저장소 | In Memory Storage | |
| 저장 방식 | Key-Value | |
| 데이터 타입 | String, Set, Sorted Set, Hash, List | String |
| 데이터 저장 | Memory, Disk | Only Memory |
| 메모리 재사용 | 메모리 재사용 하지 않음(명시적으로만 데이터 삭제 가능) | 메모리 부족시 LRU 알고리즘을 이용하여 데이터 삭제 후 메모리 재사용 |
| 스레드 | Single Thread | Multi Thread |
| 캐싱 용량 | Key, Value 모두 512MB | Key name 250 byte, Value 1MB |
프로젝트를 함에 있어 가장 큰 차이점은 얼마나 많은 자료구조를 지원하느냐 라고 생각합니다.
Memcached에 비해 Redis는 기본적으로 String, Bitmap, Hash, List, Set, Sorted Set을 제공합니다.
레디스에서 이렇게 다양한 자료구조를 지원하는것이 중요한 이유는 무엇일까요?
바로 개발의 편의성과 난이도 때문입니다.
예를 들어,
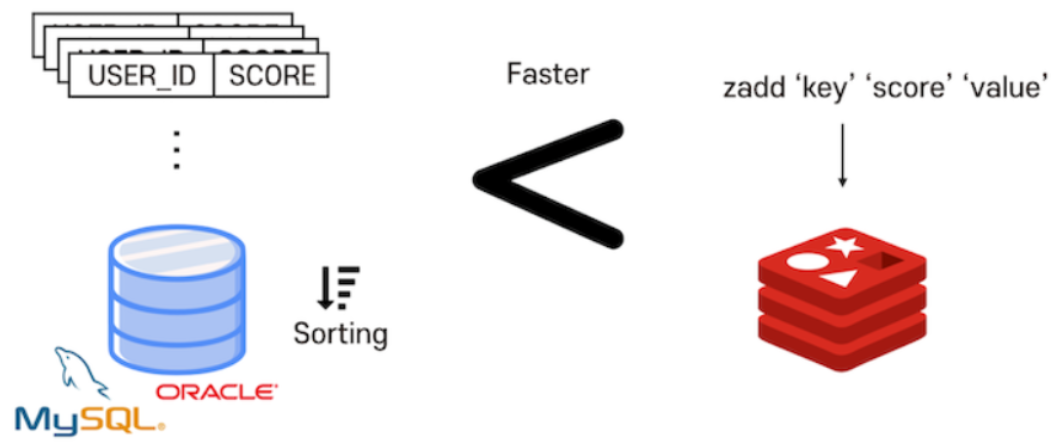
예를 들어 실시간 랭킹 서버를 구현할 때 관계형 DBMS를 이용한다면 DB에 데이터를 저장하고, 저장된 SCORE 값으로 정렬하여 다시 읽어오는 과정이 필요합니다. 이 때 레디스의 Sorted-Set을 이용하면 더 빠르고 간단하겠죠?
레디스는 트랜잭션의 문제도 해결해 줄 수 있습니다. 싱글 스레드로 동작하는 서버의 모든 자료구조는 atomic 하기 때문에, race condition을 피해 데이터의 정합성을 보장하기 쉽습니다.
즉, 외부의 Collections을 잘 이용하는 것만으로 개발 시간 단축이 가능하고, 생각하지 못한 여러가지 문제를 줄여줄 수 있으므로 개발자는 비즈니스 로직에 집중할 수 있다는 큰 장점이 존재합니다.
개발의 편의성 및 생산성을 고려했을때 저는 Redis를 쓰는 것이 더 좋을 것이라고 생각이 드네요.
그럼 마지막으로 Redis는 NoSQL인데 NoSQL과 RDBMS도 비교해볼까요?
RDBMS도 있는데 왜 세션 저장소로 NoSQL을 고려했을까요?
RDBMS에도 저장할 수 있고 MongoDB, Memcached 등 다른 NoSQL에도 데이터를 저장할 수 있습니다.
https://docs.spring.io/spring-data/data-redis/docs/current/reference/html/#reference
Spring Data Redis
Some commands (such as SINTER and SUNION) can only be processed on the server side when all involved keys map to the same slot. Otherwise, computation has to be done on client side. Therefore, it is useful to pin keyspaces to a single slot, which lets make
docs.spring.io
이 곳을 확인해보면,
왜 SpringData Redis인가? 라는 문단이 있습니다. 설명에는
"NoSQL스토리지 시스템은 수평 적 확장 성과 속도를 위해 기존 RDBMS에 대한 대안을 제공합니다. 구현 측면에서 키-값 저장소는 NoSQL 공간에서 가장 큰 (그리고 가장 오래된) 구성원 중 하나를 나타냅니다.
Spring Data Redis (SDR) 프레임 워크는 Spring의 우수한 인프라 지원을 통해 저장소와 상호 작용하는 데 필요한 중복 작업 및 상용구 코드를 제거하여 Redis 키-값 저장소를 사용하는 Spring 애플리케이션을 쉽게 작성할 수 있도록합니다."
라고 나와 있죠.
위 문단을 간단하게 요약해보자면,
NoSQL은 RDBMS에 비해 속도와 확장성이 뛰어납니다. 위 문서를 통해 MySQL과 같은 RDBMS는 속도가 중요한 캐싱에는 적합하지 않다는 것을 알 수 있습니다.
RDBMS에 비해 NoSQL이 왜 속도와 확장성이 뛰어날까요?
참고 문헌:
https://deveric.tistory.com/65
https://docs.aws.amazon.com/ko_kr/AmazonElastiCache/latest/mem-ug/SelectEngine.html
'DataBase' 카테고리의 다른 글
| [MySQL] 외래키(Foreign Key)와 데드락(DeadLock) (0) | 2021.08.12 |
|---|---|
| [MySQL] 트레픽 분산을 위한 Master/Slave DataSource 동적 라우팅 설정 (0) | 2021.08.10 |
| [DB] Redis(Remote dictionary server)란? (0) | 2021.06.16 |
| [Real MySQL 정리] 5장 인덱스 (0) | 2021.04.25 |
| [Real MySQL 정리], 4장 트랜잭션과 잠금 (0) | 2021.04.25 |



