
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Stream
- 이스티오
- 쿠버네티스
- GC
- 스프링
- mysql
- IntellJ
- Kotlin
- Real MySQL
- 보조스트림
- 자바 ORM 표준 JPA 프로그래밍
- Collection
- 백준
- JPA
- K8s
- thread
- Java
- 토비의 스프링 정리
- redis
- 토비의 스프링
- 자바
- Stack
- gradle
- jvm
- spring
- OS
- list
- SpringBoot
- 스트림
- MSA
- Today
- Total
인생을 코딩하다.
Apache Kafka는 어떤 방식으로 동작할까? 본문

Apache Kafka란?
Apache Kafka는 이벤트 스트리밍 플랫폼입니다. Kafka는 고성능 TCP 네트워크 프로토콜을 통해 통신하는 서버와 클라이언트로 구성된 분산 시스템입니다. 베어메탈 하드웨어, 가상 머신, 온프레미스 및 클라우드 환경의 컨테이너에 배포할 수 있습니다.
서버 : Kafka는 여러 데이터 센터 또는 클라우드 지역에 거쳐 있을 수 있는 하나 이상의 서버 클러스터로 실행됩니다. 이러한 서버 중 일부는 브로커라고 하는 스토리지 계층을 형성합니다. 다른 서버는 Kafka Connect 를 실행 하여 데이터를 이벤트 스트림으로 지속적으로 가져오고 내보내고 Kafka를 관계형 데이터베이스 및 기타 Kafka 클러스터와 같은 기존 시스템과 통합합니다. 미션 크리티컬한 사용 사례를 구현할 수 있도록 Kafka 클러스터는 확장성이 뛰어나고 내결함성이 있습니다. 서버 중 하나에 장애가 발생하면 다른 서버가 작업을 인계받아 데이터 손실 없이 지속적인 운영을 보장합니다.
클라이언트 : 네트워크 문제나 시스템 오류가 발생한 경우에도 이벤트 스트림을 병렬로, 대규모로, 내결함성 방식으로 읽고, 쓰고, 처리하는 분산 애플리케이션 및 마이크로서비스를 작성할 수 있습니다. Kafka 에는 Kafka 커뮤니티에서 제공 하는 수십 개의 클라이언트가 포함된 일부 클라이언트가 포함되어 있습니다. 클라이언트는 더 높은 수준의 Kafka Streams 라이브러리를 포함하여 Java 및 Scala , Go, Python, C/C++ 및 기타 여러 프로그래밍에 사용할 수 있습니다. 언어 및 REST API.
Kafka의 동작 방식
카프카는 기본적으로 메시징 서버로 동작합니다. 메세지라고 불리는 데이터 단위를 보내는 측(Publisher 또는 Producer)에서 카프카에 토픽이라는 각각의 메시지 장소에 데이터를 저장하면, 가져가는 측(Subscriber 또는 Consumer)이 원하는 토픽에서 데이터를 가져가게 되어 있습니다.
Kafka가 아닌 일반적인 형태의 네트워크 통신은 아래와 같이 구성됩니다. 전송 속도와 결과를 신속하게 알 수 있는 장점이 있는 반면 특정 개체에 장애가 발생한 경우 메시지를 보내는 쪽에서 대기 처리 등을 개별적으로 해주지 않으면 장애가 발생할 수 있습니다. 또한 통신에 참여하는 개체가 많아질수록 서로 일일이 다 연결하고 데이터를 전송해야하기 때문에 확장성이 좋지 않습니다. 주로 RabbitMQ가 이러한 방식으로 동작합니다.
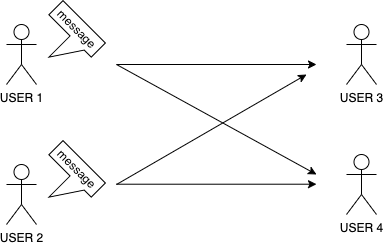
이런 형태의 단점을 극복하고자 나온 통신모델이 Pub/Sub 모델입니다.

프로듀서가 메시지를 컨슈머에게 직접 전달하는게 아니라 중간의 메시징 시스템에 전달합니다. 이 때 메시지 데이터와 수신처 ID를 포함시킵니다.
메시징 시스템의 교환기가 메시지의 수신처 ID 값을 확인한 다음 컨슈머들의 큐에 전달합니다. 컨슈머는 자신들의 큐를 모니터링 하고 있다가 큐에 메시지가 전달되면 이 값을 가져갑니다.
간단히 말해서, 기존 메시지 시스템에서는 브로커가 consumer에게 메시지를 publish 해주는 방식(RabbitMQ)인데 반해, Kafka는 counsumer가 브로커로부터 직접 메시지를 가지고 가는 pull 방식으로 동작합니다. 따라서 cunsumer은 자신의 처리 능력만큼의 메시지만 가져오기 때문에 최적의 성능을 낼 수 있습니다. 이 점을 활용하여 메시지를 쌓아두었다가 주기적으로 처리하는 batch 컨슈머의 구현이 가능해졌습니다.
위 처럼 메시징 시스템(Kafka)을 구성했을 때의 장점
1. 개체가 빠지거나 수신 불가능한 상태가 되어도 메시징 시스템만 살아있다면 프로듀서에게 전달된 메세지가 유실되지 않습니다. 이 메시지는 불능 상태의 개체가 다시 회복되면 언제든지 다시 가져갈 수 있습니다.
2. 각각의 개체가 다대다(N:N) 통신을 하는것이 아닌, 메시징 시스템을 중심으로 연결되기 때문에 확장성이 용이합니다.
따라서, 확장성을 고려한 프로젝트에서는 Kafka를 사용하는 것이 좋겠죠?
하지만 단점도 있습니다. Pub/Sub의 단점은 직접 통신을 하지 않기 때문에 메시지가 정확하게 전달되었는지 확인하려면 코드가 좀 더 복잡해지고, 중간에 메시징 시스템이 있기 때문에 메시지 전달 속도가 빠르지 않다는 점입니다.
그래서 카프카는 이러한 성능적 단점을 극복하기 위해, 메시지 교환 전달의 신뢰성 관리를 프로듀서와 컨슈머 쪽으로 넘기고, 부하가 많이 걸리는 교환기 기능 역시 컨슈머가 만들 수 있게 함으로써 메시징 시스템 내에서의 작업량은 줄이고 이렇게 절약한 작업량을 메시징 전달 성능에 집중시켜 고성능 메시징 시스템을 만들어 냈습니다.
또한 카프카는 기존의 메시징 시스템에 비해 메시지를 파일 시스템으로 저장하기 때문에 메시지를 많이 쎃어두어도 성능이 크게 감소하지 않습니다. 그리고 메시지를 쌓아둘 수 있기 때문에 실시간 처리뿐만 아니라 주기적인 batch 작업에 사용할 데이터를 쌓아두는 용도로 사용할 수 있습니다.
'Kafka' 카테고리의 다른 글
| [Kafka] 파티션이 증가할수록 commit_offset log file 리소스도 증가할까? (0) | 2025.04.06 |
|---|---|
| [Kafka] Kafka에서 파티션 증가 없이 동시 처리량을 늘리는 방법 - Parallel Consumer (2) | 2025.01.31 |
| [Kafka] 카프카 메시지 중복 컨슘, 누락이 발생할 수 있는 경우 (0) | 2024.03.03 |
| [Kafka] 컨슈머 장애로 인한 토픽<->컨슈머 자동 리밸런싱전, 컨슈머에 장애가 생긴걸 어떻게 판단하여 자동 리밸런싱이 되게 할 수 있을까 (2) | 2023.02.26 |


