
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
Tags
- 토비의 스프링
- thread
- Java
- 자바 ORM 표준 JPA 프로그래밍
- 스트림
- Collection
- GC
- mysql
- list
- Kotlin
- 보조스트림
- gradle
- jvm
- 자바
- spring
- Stack
- JPA
- Real MySQL
- K8s
- Stream
- 백준
- OS
- MSA
- 스프링
- 쿠버네티스
- IntellJ
- 토비의 스프링 정리
- SpringBoot
- 이스티오
- redis
Archives
- Today
- Total
인생을 코딩하다.
OS 정리 본문
728x90
반응형
운영 체제
1. 제어 프로그램(Kernel)
- 하드웨어를 제어하는 프로그램
- 메모리, CPU, 단말기, 프린터 등 시스템의 자원 활용도를 높이기 위해 스케줄링과 자료 관리를 하는 핵심 요소이다.
2. 명령어 해석기(Shell)
- 사용자의 명령을 입력받아 시스템 기능을 수행하는 명령 해석기
- 사용자와 시스템 간의 인터페이스를 담당하는 프로그램이다.
3. 매크로
- 어셈블리어를 사용하기 쉽도록 명령어들을 문자로 치환하여 확장해 준다.
- 메크로 라이브러리는 여러 프로그램에서 공통적으로 자주 사용되는 매크로들을 모아 놓은 라이브러리다.
- 매크로는 일정의 문자열 치환과 같이 사용된 횟수만큼 명령어를 생성, 삽입하여 실행한다.
- 매크로 내에 또 다른 매크로를 정의할 수 있다.3-1. 매크로 프로세서의 기본 기능
- 매크로 정의 인식 : 매크로를 정의한 부분의 시작과 종료를 파악한다.
- 매크로 정의 저장 : 매크로 프로세서는 매크로명과 정의된 내용을 매크로 호출시 확장하기 위해 저장한다.
- 매크로 호출 인식 : 매크로가 확장하기 위한 준비가 되어 있는지 확인한다.
- 매크로 확장 및 인수 : 매크로명이 있는 원시 프로그램 위치에 저장된 내용과 인수를 치환한다.
4. 로더(Loader)
- 목적 프로그램(기계어로 구성된 파일)을 실행 가능한 파일로 변환하기 위해 주기억 장소를 할당(Allocation) 하거나, 여러 개의 목적 프로그램을 연계 편집하여 CPU가 처리될 수 있는 프로그램으로 변환한다.
- 프로그램을 실행하기 위하여 프로그램을 보조 기억 장치로부터 컴퓨터의 주기억 장치에 올려 놓는 것을 좁은 의미의 로더
- 목적 프로그램들끼리 연결(Linking)시키거나 주기억 장치를 재배치(Relocation)하는 등의 포괄적인 작업을 하게 되는 것을 넓은 의미의 로더4-1. 로더의 기능
- 할당 -> 연결 -> 재배치 -> 적재 순으로 진행된다.
- 할당(Allocation) : 목적 프로그램이 실행될 주기억 장치(RAM)의 공간을 확보한다.
- 연결(Linking) : 여러 개의 독입적인 모듈을 연결한다.
- 재배치(Relocation) : 프로그램이 주기억 장치 공간 안에서 위치를 변경할 수 있게 한다.
- 적재(Loading) : 프로그램 전체를 주기억 장치에 한 번에 적재하게 하거나, 실행 시 필요한 일부분만을 차례로 적재하게 한다.
- Compile and Go 로더 : 번역 프로그램과 로더가 하나로 구성되어 번역 프로그램이 로더의 역할까지 담당하는 방식
- 절대 로더 : 로더의 역할이 축소되어 가장 간단한 프로그램으로 구성된 것으로 기억 장소 할당이나 연결을 프로그래머가 직접 지정하는 방식이다.
- 직접 연결 로더 : 로더가 할당, 연결, 재배치, 적재를 모두 수행하는 일반적인 형태이다.
- 기타 로더 : Binding 로더, Module 로더, 동적 적재 로더(CPU가 현재 사용중인 부분만 적재하고 미사용 중인 프로그램은 보조 기억 장치에 저장해 두는 방식, Load-On-Call)
5. 프로세스(Process)
- 로더에 의해 주기억 장치에 상주된 프로그램이 CPU에 의해서 처리되는 상태
- CPU에 의해 현재 실행되고 있는 프로그램이다.
- PCB(Process Control Block, 프로세스 제어 블록)의 존재로서 명시되는 것이다.
- 프로세서(Processor)가 할당되는 개체로서, 디스패치(Dispatch)가 가능한 단위이다.
- 지정된 결과를 얻기 위한 일련의 계통적 동작이다.
- 목적 또는 결과에 따라 발생하는 사건들의 과정이다.
- 비동기적 행위를 일으키는 주체이다.
- 프로시저가 활동 중인 상태를 말한다.
- 실행중인 프로시저의 제어 궤적이다.
- CPU가 할당되는 실체이다.
- 운영체제가 관리하는 최소 단위의 작업 프로그램이다.5-1. 프로세스의 상태
- 프로세스의 상태 전이도는 CPU를 사용할 때, 사용하기 전, 입출력을 행하는 상태로
- 실행(Run), 준비(Ready), 대기(Block) 상태로 구분할 수 있다.
- 준비(Ready)
- 프로세스가 처리기(CPU)를 사용하고 있지는 않지만 언제든 사용할 수 있는 상태다.
- 프로세스가 처리기의 배정을 기다리고 있는 상태다.
- 다른 프로세스 실행을 위해 일시적으로 정지해 있는 상태다.
- CPU에 의해 처리되기 위해 주 기억장치에 존재하는 상태이다.
- 실행(Run)
- 프로세스가 CPU를 차지하고 있는 상태다.
- 프로세스의 명령이 실행되고 있는 상태다.
- 대기(Block, Wait, 보류)
- 프로세스가 어떤 사건이 일어나기를 기다리고 있는 상태다.
- 처리 속도가 느린 입출력 작업 중인 상태다.
- 외부적인 사건이 생길 때 까지 실행할 수 없는 상태다.

6. 디스패치(Dispatch), 스풀(Spool), 버퍼링(Buffering)
- 디스패치
- 준비 상태에 있는 여러 프로세스중 프로세스를 선정하여 CPU를 할당하는 시점
- 스풀
- 프로그램과 이를 이용하는 I/O 장치와의 속도 차를 극복하기 위한 장치로 대부분 하드 디스크가 중재한다.
- 버퍼링
- CPU와 입출력 장치와의 속도 차이를 줄이기 위해 메모리가 중재한다.
7. 인터럽트(Interrupt)
- 프로세스가 수행 중에 다른 프로세스를 수행하기 위하여 현재 수행중인 프로세스를 중단하거나 외부 입력 장치에 의해 프로세스가 중단되는 상태
- 현재 프로세스를 중단시키는 모든 행위7-1. 인터럽트 처리 순서
- 인터럽트가 발생하면 운영체제가 제어권을 받는다.
- 운영체제는 인터럽트 받은 현태의 프로세스 상태를 저장한다.
- 운영체제는 인터럽트의 정보를 분석하여 지정되어 있는 루틴으로 제어권을 넘겨준다.
- 인터럽트 처리 루틴이 인터럽트를 처리한다.
- 인터럽트가 걸렸던 이전 프로세스의 상태로 복구된다.
- 인터럽트가 걸렸던 시점 이후부터 프로세스가 실행된다.
- SVC(SuperVisor Call) 인터럽트
- 운영체제의 감시 프로그래믈 호출하면 발생
- 사용자로부터 운영체제를 보호하거나 입출력 수행 루틴 호출, 기억 장치 할당, 오퍼레이터와의 대화등을 위해 발생하는 인터럽트이다.
- 입출력(I/O) 인터럽트
- 하드웨어적 인터럽트로 입출력 채널 확인, 준비, 할당, 완료 시에 발생한다.
- 외부(External) 인터럽트
- 인터럽트 시계에 의해 프로세스가 시간 할당량이 종료된 경우 발생한다.
- 재시작(Restart) 인터럽트
- 자용자가 재시작을 하는 경우이다.
- 프로그램 검사(Program Check) 인터럽트
- Overflow, Underflow 상태시, 나눗셈에서 분모가 0인 경우
- 기계 검사(Hardware Check) 인터럽트
- 시스템의 기계 고장
8. 문맥 교환(Context Switching)
- CPU가 할당되는 프로세스를 변경하기 위하여 현재 CPU를 사용하여 실행되고 있는 프로세서의 상태 정보를 저장하고 제어권을 인터럽트 서비스 루틴(ISR)에게 넘기는 작업8-1. 문맥 교환의 위치
- 프로그램 실행 : 인터럽트 발생
- 프로그램 중단 : 현재 처리 중인 프로그램 잠시 중단
- 문맥 교환 : 두 개의 프로그램 정보 교환
- 인터럽트 처리 : 새롭게 실행된 프로그램 처리
- 인터럽트 서비스 루틴(ISR) : 새롭게 실행된 프로그램의 부가적인 서비스 루틴 수행
- 프로그램 중단 부분 재실행 : 중단되었던 기존에 프로그램 실행
- 프로세스의 중단과 실행 시 인터럽트가 발생하므로, 문맥 교환이 많이 일어난다는 것은 인터럽트가 많이 발생한다는 것이다.
- 시간 할당량이 적어지면 : 문맥 교환 수, 인터럽트 횟수, 오버헤드가 증가하지만 여러 개의 프로세스가 동시에 수행되는 느낌을 가진다.
- 시간 할당량이 많아지면 : 문맥 교환 수, 인터럽트 횟수, 오버헤드가 감소하지만 여러 개의 프로세스가 동시에 수행되지 못하는 느낌을 가진다.
9. 프로세스 제어 블록(PCB : Process Control Block)
- 운영체제 내에서 한 프로세스의 존재를 정의
- 여러개의 프로세스를 수행하는 다중 프로그래밍 환경 하에서 각 프로세스를 구분하기 위한 프로세스 정보 블록이다.9-1. PCB 항목
- 프로세스 식별자
- 프로세스 현재 상태 : 준비, 실행, 대기 상태를 기억시킨다.
- 프로그램 카운터(계수기) : 다음에 실행되는 명령어의 주소를 기억시킨다.
- 프로세스 우선순위
- 프로세스가 적재된 기억 장치 부분을 가리키는 포인터 : 프로세스가 시작되는 기억 장치의 시작 번지를 기억시킨다.
- 프로세스에 할당된 자원을 가리키는 포인터 : 프로세스 처리 중에 필요한 자원의 정보를 갖고 있는 기억 장소의 시작 번지를 기억한다.
- 처리기(CPU) 레지스터 정보
- CPU의 각종 레지스터 상태를 가리키는 포인터
- 계정 정보
- 기억 장치 관리 정보
- 입출력 정보
- 부모 프로세스를 가리키는 포인터
- 자식 프로세스를 가리키는 포인터
10. CPU 스케줄링
- 최적의 효과(처리율 향상, 신속한 처리 등)을 보기 위해서는 프로세스의 계획적인 실행 순서가 필요하다.
- 계획적인 실행 순서를 CPU 스케줄링 / 프로세스 스케줄링 이라고 한다.10-1. 스케줄러 종류
- 상위 수준의 스케줄러 : CPU가 아닌 시스템 내의 자원들을 관리하는 수준
- 중위 수준의 스케줄러 : 어느 프로세스부터 CPU를 사용할 수 있는지를 결정하는 CPU 스케줄러
- 하위 수준의 스케줄러 : CPU 사용 중에 보류와 디스패치 시기를 결정하는 프로세스 스케줄러를 의미
- 프로세스 스케줄링은 CPU나 자원을 효과적이며 생산성있게 사용하기 위한 소프트웨어적 계획을 의미
- 필요한 하드웨어 레지스터를 설정함으로써 프로세스에게 CPU를 할당하고 문맥 교환을 하는 프로세스 관리 기능이다.
- 모든 프로세스에게 공정하게 배정
- 단위 시간당 가능한 최대한 많은 양이 처리될 수 있도록 한다.
- 응답 시간이 신속해야 한다.
- 같은 종류의 작업은 거의 같은 시간과 비용으로 실행될 수 있어야 한다.
- 오버헤드를 최소화해야 한다.
- 시스템 내의 자원이 사용하지 않는 시간이 없도록 유지해야 한다.
- 응답 시간과 자원의 활용 간 적절한 균형이 유지되도록 해야 한다.
- 프로세스가 무한정 기다리게 하는 것을 피해야 한다.
- 프로세스의 상태를 파악하여 우선순위를 부여 하는 것이 좋다.
- 중요 자원을 차지하고 있는 프로세스에게 우선권을 주어야 한다.
- 문제로 인해 불안하지 않은 프로세스에 서비스를 많이 제공하도록 한다.
- 부하가 많은 경우 갑자기 체증이 발생하지 않도록 조절한다.
- CPU 이용률
- 처리 능력(Throughput)
- 대기 시간
- 응답 시간
- 반환 시간
11. 비선점형 프로세스 스케줄링(Non Preemptive)
- 프로세스가 CPU에 할당되면 권한을 빼앗을 수 없다.
- 일괄 처리 방식에 적당하다.
- 대화형, 시간분할, 실시간 시스템에 부적절하다.
- FIFO, SJF, HRN, 우선순위, 기한부 방식
- 문맥 교환이 적어 오버헤드가 적다.11-1. FIFO(First Input First Out, FCFS : First Come First Served)
- 먼저 입력된 작업을 먼저 처리한다.
- 가장 대표적인 비선점형 방식
- 공평하고 구현이 간단하나 평균 반환 시간이 길다.
- 짧은 작업이나 중요한 작업을 오랫동안 기다리게 할 수 있다.
- 작업이 끝나기까지의 실행 시간 추정치가 가장 작은 작업을 먼저 실행 시킨다.
- 크기가 큰 작업들을 어느 정도는 희생시키면서 짧은 작업들을 우선으로 처리하기 때문에 대기 리스트 안에 있는 작업의 수를 최소화 하면서 평균 반환 시간을 최소화할 수 있다.
- 긴 작업일지라도 이미 CPU를 점유하고 있다면 뒤로 밀려나지 않고 처리되고 다음 작업들을 대상으로 재정리 한다.
- 짧은 작업들 때문에 우선순위가 계속 밀려 나면서 긴 작업들은 무한 연기 상태가 발생할 수 있다.
- 평균 대기 시간을 최소화 한다.
- 무한 연기 현상을 방지하기 위해 Aging 기법을 사용하여 해결한다.
- Aging 기법 : 자원이 할당되기를 오랜 시간 동안 기다린 프로세스는 기다린 시간에 비례하는 높은 우선순위를 부여하여 가까운 시간 안에 자원이 할당되도록 하는 기법이다.
- 실행 시간 추정과 선점 기능 때문에 스케줄러가 복잡해지고 남은 계산 시간들을 저장해 놓아야 하는 단점을 보안
- 서비스 시간(실행 시간 추정치)과 대기 시간의 비율을 고려한 스케줄링
- 대기 리스트에 있는 작업들에게 합리적으로 우선순위를 부여하여 많고, 적은 작업들의 불평등을 해소한 방식으로 SJF의 단점을 보안환 방식
- 우선 순위 계산 공식을 이용한다.
- 우선순위 = (대기 시간 + 서비스 시간) / 서비스 시간 (서비스 시간 = 실행(추정) 시간)
- 대기 리스트에 있는 프로세스들에게 작업의 우선순위를 부여하여 CPU를 할당하는 방법
- 중요한 작업을 먼저 할 수 있다.
- 기아 현상, 무한 봉쇄 현상이 발생할 수 있다.
- 작업이 주어진 특별한 시간이나 만료 시간 안에 완료되도록 하는 방식이다.
- 프로세스들이 마감 시간 내에 처리되지 않으면 폐기되거나 다시 처음부터 실행해야 한다.
- 기한부 스케줄링에 필요한 집약적 자원 관리는 많은 오버헤드를 일으킬 수 있다.
- 동시에 다수의 기한부 작업이 수행되면 스케줄링은 매우 어려워진다.
- 사용자는 작업에 필요한 자원의 정보를 정확한 정보를 시스템에 제시하여야 한다.
- 프로세스 양이 늘어나면 오버헤드 측면에서 안정적이지 못하다.
12. 선점형 프로세스 스케줄링(Preemptive)
- 프로세스가 CPU에 할당되면 우선순위가 높으면 빼앗을 수 있다.
- 일괄 처리 방식에 부적당하다.
- 대화형, 시간 분할, 실시간 시스템에 적당하다.
- RR, SRT, MFQ
- 문맥 교환이 많아 오버헤드가 많다.12-1. RR(Round Robin, 라운드 로빈)
- 시분할 시스템을 위해 고안
- 여러 개의 프로세스가 어느 정도의 시간 할당량이라는 작은 단위 시간이 정의되어 시간 할당량만큼씩 CPU를 사용하는 방법
- FIFO를 선점형으로 한 방식
- CPU에게 할당 받은 시간동안 작업을 완료하지 못하면 CPU는 다음 대기 중인 프로세스에게로 사용 권한이 넘어가고 현재 실행 중이던 프로세스는 대기 리스트(Ready List)의 가장 뒤로 배치된다.
- 할당된 시간 : Time Slice, Quamtum
- 적절한 응답 시간을 보장해 주는 대화식 사용자에게 효과적이다.
- 동일한 시간을 사용하는 시분할 시스템에 효과적이다.
- 시간 할당량이 적은 경우 문맥 교환에 따른 오버헤드가 커진다.
- 시간 할당량이 너무 작으면 문맥 교환수가 증가한다.
- 시간 할당량이 너무 작으면 오버헤드가 커지게 된다.
- 시간 할당량이 너무 작으면 프로세서의 교환에서 시간을 소비하고 실제 사용자들의 연산은 거의 못한다.
- 시간 할당량이 너무 크면 FIFO와 같은 형태가 된다.
- 시간 할당량이 너무 크면 CPU를 사용하지 않는 시간이 많아진다.
- 작업이 끝나기까지 '남아 있는' 실행 시간의 추정치가 가장 작은 프로세스를 먼저 실행한다.
- 새로 입력되는 작업까지도 포함이다.
- 남아 있는 프로세스의 실행 추정치가 더 작은 프로세스가 있다면 언제든지 현재 작업 중인 프로세스를 중단하여 더 작은 프로세스에게 CPU를 넘겨주게 되는 방식
- 서비스 받은 시간을 기록해야 하므로 오버헤드가 늘어난다.
- 평균 대기 시간과 대기 시간의 분산도 크다.
- 실행 시간을 추적해야 하므로 오버헤드가 증가한다.
- 임계치(Threshold Value)를 사용한다.
- Threshold Value : CPU를 사용 중인 프로세스가 거의 막바지에 이르렀을 때 남아 잇는 시간보다 조금 작은 프로세스가 입력된다면 CPU 사용 권한을 넘겨줘야 할 것이다. 하지만 이럴 경우 문맥 교환 횟수나 전체 정황으로 보았을 때 현재 작업 중인 프로세스를 모두 마치고 조금 작은 프로세스를 다음에 처리하는 것이 더 효율적일 것이다. 이 수치 값이 Threshold Value(임계치)다.
- 맨 위에 있는 큐가 가장 우선순위가 높고 시간 할당량도 적다.
- 아래로 갈수록 우선순위가 낮고 시간 할당량은 크게 배치된다.
- 각 큐는 자신보다 낮은 단계의 대기 리스트들에서 절대적인 우선순위를 갖게 된다.
- A 대기 리스트에서 작업하던 프로세스가 정해진 시간 할당량을 사용하고 남게 되면 중단 시키고 나머지 작업에 대해서는 B 대기 리스트로 이동하고 다음 프로세스에게 CPU를 할당한다. 나머지도 대기 리스트도 마찬가지다.
- 가장 낮은 대기 리스트는 맨 마지막이기 때문에 라운드 로빈 스케줄링으로 운영한다.
- B 대기 리스트에 있는 프로세스들은 A 대기 리스트에 프로세스가 존재하지 않아야만 CPU를 사용할 수 있다.
- 만약 B 대기 리스트에 있는 프로세스가 CPU를 사용 중일 때 A 대기 리스트에 프로세스가 입력되면 바로 중단하고 A 대기 리스트에 있는 프로세스에 CPU 사용 권한을 넘겨주어야 한다.
- 짧은 작업이나 CPU를 적게 사용하는 입출력 작업들은 최상위 큐에서 빨리 처리하자는 것이다.
- 짧은 작업이나 입출력 위주의 작업에 우선권을 부여하기 위해 개발된 방식으로 적응 기법의 개념을 적용한다.
- 큐마다 시간 할당량(Quantum)이 존재하며 낮은 큐일수록 시간 할당량은 커진다.
- 각각의 큐들은 종속적으로 연결되어 있다.
- 맨 위의 큐가 가장 우선순위가 높고, 아래로 갈수록 우선순위가 늦게 구성된다.
- 우선순위가 가장 낮은 작업들은 대부분 응답 속도가 빠르지 않아도 되는 일괄 처리형 큐를 사용한다.
- 각 큐들은 자신보다 낮은 단계의 큐에서 절대적인 우선순위를 갖게 된다.
- 우선순위가 가장 높은 대기 리스트에 존재하느 프로세스는 어떠한 경우라도 프로세스를 빼앗기지 않는 비선점형이다.
- 나머지 대기 리스트에 존재하는 프로세스들은 우선순위가 높은 큐에 프로세스가 입력되면 CPU를 빼앗기게 되므로 선점형이 된다.
- 다단계 큐는 선점과 비선점을 결합한 스케줄링이다.
- 대기 리스트를 특성별로 여러 개 가진다.
- 대기 리스트마다 독립적인 스케줄링을 가진다.
- 대기 리스트 간에 프로세스가 이동이 안 된다.


13. 임계 구역(Critical Section, 위험 지구)
- 다중 프로그래밍 운영체제에서 한 순간에 여러 개의 프로세스에 의하여 공유되는 데이터 및 자원에 대하여 반드시 하나의 프로세스에 의해서만 자원 또는 데이터가 사용되도록 하는 것
- 자원이 프로세스에 의하여 반납된 후, 비로소 다른 프로세스에서 자원을 이용하거나 데이터를 접근할 수 있도록 지정된 영역
- 여러 개의 프로세스가 공동으로 사용하는 CPU, 메모리, 디스크, 입출력 장치 등을 임계구역
- 서로 동시에 접근 되어서도 안 되며, 독점할 수도 없다.
- 두 개 이상의 프로세스가 하나의 결과 값을 얻기 위해 하나 이상의 기억 장소를 공유하게 되면서 순차적으로 사용한다면, 이러한 공유 기억 장소를 임계 구역이라 할 수 있다.13-1. 임계 구역의 원칙
- 두 개의 프로세스가 동시에 사용할 수 없다.
- 순서를 지키면서 신속하게 사용한다.
- 하나의 프로세스가 독점하게 해서는 안 된다.
- 사용 중에 무단, 무한 반복되어서도 안 된다.
- 인터럽트가 불가능한 상태로 만들어야 한다.
- 한 프로세스가 임계 구역을 수행 중일 경우, 어떤 프로세스도 임계 구역을 수행해서는 안 된다.
- 한 프로세스가 임계 영역에 대한 진입 요청 후, 일정 시간 내에 진입을 허락해야 한다.
- 현재 임계 구역에서 실행되는 프로세스가 없는 경우, 잔류 영역 이외에 있는 프로세스는 임계 구역에 진입할 수 없다.
- 임계 구역 내의 프로세스는 다른 프로세스가 임계 구역 내로 들어오는 것을 허용할 수 있는 권한은 없다.
14. 상호 배제(Mutual Exclusion)
- 임계 구역(공유 자원)을 어느 시점에서 단지 한 개의 프로세스만이 사용할 수 있도록 하며, 다른 프로세스가 현재 사용 중인 임계 구역(공유 자원)에 대하여 접근하려고 할 때 금지하는 행위
- 인터럽트 불능 처리, 잠금, 엄격한 교대, TSL, 세마 포어14-1. 상호 배제 알고리즘
- 인터럽트 불능 처리 : 하나의 프로세스가 하나의 공유 자원(임계 구역)을 점유하게 되면 인터럽트를 발생하지 않도록 봉쇄한다.
- 잠금 : 공유 자원을 점유하게 되는 경우 그 자원을 어떠한 프로세스도 접근하지 못하도록 하는 방법이다.
- 엄격한 교대 : 두 개 이상의 프로세스가 교대로 공유 자원을 점유하는 방식이다.한쪽이 작업량이 많아서 빈번해져도 반드시 교대로 점유해야 한다.한쪽 프로세스가 점유 시간이 길어지면 나머지 프로세스는 사용 가능한가를 계속 감지하는 작업을 반복해야 한다.
- 하나의 프로세스가 사용 중에 중단되면 다른 프로세스는 교착상태에 빠지게 된다.
- 엄격한 교대의 문제점 : 항상 하나의 프로세스가 우선권을 가지게 해야 한다.
- TSL(Test & Set Lock) : 특수한 하드웨어 자원을 필요로 하지만, 바쁜 대기 상태는 완벽히 해결하지는 못한다.프로세스 A가 공유 자원을 사용하기 위해선 B의 변수가 0인가를 확인한다. 1이면 프로세스 B 가 사용중이다.
- 프로세스 A, B 모두 각자의 변수를 가지게 되며, 각 프로세스의 변수의 값이 모두 0일 때 공유 자원을 사용할 수 있다.
- Sleep(), Wakeup() : 하나의 공유 자원을 점유하기 위한 시도를 반복하지 않고 사용하려는 공유 자원이 이미 사용 중이라면 프로세스를 잠시 중단한다.(Sleep()) 이후 어느 정도 시간이 지나서 공유 자원이 사용 가능하다면 잠시 중단했던 프로세스를 활성화(Wakeup())하여 바쁜 대기 현상을 방지하는 방법이다.
15. 세마포어(Semaphore)
- 프로세스 간의 상호배제 및 동기화 문제 해결 방법이다.
- P(S), V(S) 등의 연산을 통해서 프로세스 사이의 동기를 유지하고 상호배제의 원리를 보장한다.15-1. 세마포어 종류
- 이진 세마포어 : 세마포어 변수가 오직 0과 1값을 가지며 하나의 임계 구역(공유 자원)만을 상호배제하기 위한 알고리즘으로 잠금, 엄격한 교대, TSL 등이 있다.
- 산술 세마포어 : 세마포어 변수가 0과 양의 정수를 값으로 가지며 임계 구역을 여러 개 관리하기 위한 상호배제 알고리즘이다.
- 하나의 시스템에 공유 자원이 10개 있다는 가정하에 여러 개의 프로세스가 사용 중인 자원이 4개이고 현재 남아 있는 자원이 6개라고 한다면 세마포어 변수값은 6이 된다.
- 임의의 프로세스가 자원을 요청 : 자원이 0이 남아 있다면 운영체제는 자원 분배 작업을 잠시 중단(Sleep)한다. 그렇지 않다면, S = S-1
- 임의의 프로세스가 사용 중인 자원을 반납 : 자원이 0이 남아 있다면 운영체제를 활성화 시키고(Wakeup()) S = S+1
- 상호배제를 위한 알고리즘이다.
- 상호배제의 원리를 보장하는 데 사용된다.
- 여러 개의 프로세스가 동시에 그 값을 수정하지 못한다.
- 세마포어에 대한 연산(오퍼레이션)은 처리 중에 인터럽트되어서는 안 된다.
- 세마포어에 대한 연산은 소프트웨어나 하드웨어로 구현 가능하다.
- 이진 세마포어는 오직 0과 1의 두 가지 값을 가지며, 산술 세마포어는 0과 양의 정수를 가질 수 있다.
- 세마포어 알고리즘은 프로세스 사이의 동기를 유지하게 한다.
- V 조작은 블록 큐에 대기 중인 프로세스를 깨우는 신호(Wake-up)로서, 흔히 Signal 동작이라 한다.
- P 조작은 임계 영역을 사용하려는 프로세스들의 진입 여부를 결정하는 것으로, 흔히 Wait 동작이라 한다.
16. 모니터(Monitor)
- 상호배제를 위한 데이터 및 프로그램 모듈로 운영체제 내부의 프로그램을 모니터라고 한다.
- 공유 자원을 사용하기 위해 기다리는 프로세스들은 모니터에 진입해도 좋다는 허가를 기다리며, 모니터에서는 프로세스들의 공유 자원 점유 순서를 제어한다.16-1. 모니터의 특징
- 두 개 이상의 프로세스가 특정 공유 자원을 순차적으로 할당하는 데 필요한 데이터 및 프로시저(프로그램, 모듈, 함수)를 포함하는 병행성 구조(Concurrency Construct)이다.
- 모니터 내의 자원을 원하는 프로세스는 반드시 해당 모니터의 진입부(Entry)를 호출해야 한다.
- 모니터 외부의 프로세스는 모니터 내부의 데이터를 직접 액세스할 수 없다.
- 자료 추상화와 정보 은폐(Information Hiding)의 개념을 기초적으로 사용한다.
- 스위치 개념을 사용하여 한순간에 하나의 프로세스만 모니터에 진입이 가능하다.
- 모니터에서 사용되는 연산은 Wati와 Signal이 있다.
- 모니터의 경계에서 상호배제가 시행된다.
17. 교착상태
- 두 개 이상의 프로세스가 하나의 자원을 공유하여 사용하고 있을 때 서로가 사용 중인 자원을 요구하지만, 요구를 영원히 들어줄 수 없는 상태를 말한다.17-1. 교착상태 발생 필수 4대 요소(필요 충분 조건)
- 상호배제(Mutual Exclusion)
- 점유와 대기(Hold & Wait)
- 비선점(Non Preemption)
- 순환 대기(Circular Wait, 환형 대기)
- 교착상태 예방(Prevention) : 교착상태가 절대 발생하지 않도록 사전에 조치를 취하는 방안이지만, 성능은 떨어질 수밖에 없다.
- 상호배제 부정 : 단일 프로그램을 운영하거나, 자원을 독립적으로 사용하여 임계 구역을 없애고 상호배제를 하지 않는다면 교착상태는 절대 발생하지 않는다.
- 점유와 대기 부정(대기 제거) : 각 프로세스는 한 번에 자신에게 필요한 모든 자원을 요구해야 하며, 이 요구가 만족되지 않으면 작업을 진행할 수 없다. 또한 어떤 자원을 갖고 있는 프로세스가 더 이상 요구가 수용되지 않으면 원래 갖고 있던 자원을 일단 반납하고 필요하다면 다시 그 자원이나 다른 자원을 요구해야 한다.
- 비선점 부정(선점 인정) : 프로세스가 점유하고 있는 자원들을 언제든 빼앗을 수 있도록 한다.
- 순환 대기 부정(순환 상태를 선형 대기 상태로 변환) : 모든 프로세스에 각 자원 유형별로 할당 순서를 부여한다. 즉 한 프로세스가 주어진 유형의 자원을 할당받았으면 그 프로세스는 순서에 따라 나중에 위치하는 유형의 자원만을 요구할 수 있게 한다.
- 교착상태 회피(Avoidance) : 프로세스가 자원을 요구할 때 시스템이 안정 상태를 유지할 수 있는 프로세스의 자원 요구만을 할당해 주는 방안으로, 교착상태가 발생하지 않는 범위 내에서 자원 분배를 하는 방안이다. 다익스트라이의 은행원 알고리즘이 대표적이다.
- 은행원 알고리즘(Banker`s Algorithm)
- 불안전 상태와 안전 상태로 구분한다.
- 안전 상태에선 교착상태가 발생하지 않는다.
- 은행원 알고리즘을 적용하기 위해선 자원의 양이 일정해야 한다.
- 은행원 알고리즘을 적용하기 위해선 사용자의 수가 일정해야 한다.
- 은행원 알고리즘은 모든 요구를 유한 시간(정해진 시간) 안에 할당하는 것을 보장해야 한다.
- 은행원 알고리즘은 응답 시간이 보장되어야 하는 대화식 시스템(Interactive System)에 적용하기 어렵다.
- 교착상태는 불안정 상태지만, 불안정 상태는 교착상태가 아니다.
- 교착상태 회복(Recovery) : 실행을 중단시키거나 점유 중인 자원을 빼앗을 프로세스를 찾는 일로 가능한 손실이 적은 쪽을 선택해야 한다. 따라서 우선 프로세스를 중단하고, 중단해서도 회복이 안되면 제거해야 한다.
- 선점을 통한 회복 : 보유하고 있는 자원을 빼앗아 교착상태를 해결하고 시스템을 정상으로 회복하는 방법이다.
- 복귀를 통한 회복 : 교착상태가 발생하기 이전 상태로 복귀하여 다시 실행하는 방법이다.
- 제거를 통한 회복 : 우선순위가 낮은 프로세스를 선택하여 제거한다.
- 사용자의 조치 경로 선택 : 사용자가 직접 중단
18. 인터리빙(Interleaving)
- 주기억 장치의 엑세스 속도를 빠르게 하기 위한 기술이다.
- 기억 장치의 연속된 위치를 서로 다른 뱅크로 구성하여 하나의 주소로 여러 개의 위치에 해당하는 기억 장치를 접근 할 수 있도록 하는 방법이다.
- 하나의 장치가 독립적인 기능을 하는 다른 장치의 상태를 검사할 수 있도록 허가하는 기법을 폴링(Polling)이라고 한다.
19. DMA(Direct Memory Access)
- CPU를 거치지 않고 직접 주기억 장치와 주변 장치 사이에서 데이터를 주고받는 입출력 제어기이다.
- 입출력에 대한 CPU의 부담을 줄이는 동시에 엑세스 속도를 향상시킨다.
- 사이클 스틸링(Cycle Stealing) 기법을 사용한다.
- Cycle Stealing : 중앙 처리 장치와 입출력 장치가 동시에 주기억 장치에 접근하려는 경우, 입출력 장치에 우선순위를 부여하는 것으로, 적응 양의 사이클을 필요로 하는 채널에 우선순위를 높여 주면 입출력 장비의 효율이 높아진다.
20. 주 기억 장치 다중 프로그래밍
- 주기억 장치를 여러 개의 독립적인 프로그램으로 분리해수 사용할 수 있도록 주기억 장치를 분할해야 한다.
- 프로그램의 크기를 분할된 최대 크기보다 작거나 같도록 해야 한다.20-1. 고정 분할(정적 분할)
- 주기억 장치의 크기를 다르게 분할하되 항상 고정된 크기를 갖는 형태로 분할하는 방식
- 크기 차이로 남거나 모자라는 현상을 단편화(Fragmentation)
- 단편화는 통합(Coalescing)과 집약(Compaction, Garbage-collection)을 통해서 재사용되어야 한다.
- 내부 단편화(Internal Fragmentation) : 정해진 크기에 프로그램을 할당하고 남은 기억 공간, 사용되지 못하는 공간이다.
- 외부 단편화(External Fragmentation) : 정해진 크기는 아니지만, 프로그램의 크기가 커서 기억할 수 없게 된 공간이다.
- 프로그램이 실행되기 위해서는 프로그램 전체가 주기억 장치에 위치하고 있어야 한다.
- 프로그램이 분할된 기억 공간 안에 모두 들어갈 수 없는 경우가 생길 수 있다.
- 주기억 장치를 공정 분할하여 사용하는 방식은 내부, 외부 단편화가 모두 발생한다.
- 프로그램의 크기에 따라 주기억 장치 분할 크기를 동적으로 분할하는 방식이다.
- 프로그램의 크기에 따라 그때그때 분할하는 방식이다.
- 내부 단편화는 발생하지 않지만 외부 단편화는 계속 발생하며 차폐 레지스터의 값을 매번 변경해야 하기 때문에 고정 분할 방식보다 복잡하다.
- 기억 장치의 활용률이 높아진다.
- 고정 분할 방식에 비해 실행될 프로세스 크기에 대한 제약이 완화된다.
- 미리 크기를 결정하지 않고 실행할 프로세스의 크기에 맞게 기억 장치를 분할하기 때문에 가변 분할 기억 장치 배당 방식이라고도 한다.
- 베이스 레지스터(Base Register) : 주기억 장치(메모리)가 분할된 영역으로 나뉘어 관리될 떄, 프로그램이 한 영역에서 다른 영역으로 옮겨지더라도 명령의 주소 부분을 바꾸지 않고 정상적으로 수행될 수 있도록 하기 위한 레지스터이다.
- 차폐 레지스터(Fence Register) : 주기억 장치(메모리)가 분할된 영역으로 나뉘어 관리될 때, 분할된 영역을 다른 프로그램이 사용하지 못하도록 분할 영역의 위치(주소)를 기억하고 있는 레지스터
- 경계 레지스터(Boundary Register) : 주기억 장치(메모리)가 분할된 영역으로 나뉘어 관리될 때, 주기억 장치(RAM) 내에 존재하는 프로그램은 크게 운영체제와 사용자 영역에 존재하는 프로그램으로 나뉜다. 이 때 사용자 영역에 존재하는 프로그램이 운영체제 영역을 침범하지 못하도록 하는 것이 경계 레지스터다.
- 기억 장치 보호 키(Storage Protection Key) : 기억 장치 관리 기법중 세그먼트 기법에서 사용하는 기억 장치 보호 기법. 주기억 장치 내에 하느이 프로그램이 여러 개의 분할된 프로그램 조각(Segement)들로 분리되어 사용될 때 여러 개의 분할된 프로그램 조각들은 같은 종류의 프로그램이라는 것을 표시해야만 한다. 이러한 구분 표시는 다른 프로그램과 섞이지 않고 보호하게 된다.
- 사용할 수 없는 기억 공간을 하나로 모을 수 있도록 주기억 장치 내의 프로그램을 재구성하면 다시 사용할 수 있는 기억 공간이 생기게 될 것이다.
- 통합(Coalescing) : 인접한 공백들을 더 큰 하나의 공백으로 만드는 과정으로 차폐 레지스터의 값을 변경하여 분할 영역의 크기를 바꾸게 된다.
- 집약(압축, Compaction, Garbage-collection) : 서로 떨어져 있는 여러 개의 낭비 공간을 모아서 하나의 큰 기억 공간을 만드는 과정, 사용되지 않은 기억 장치를 주기억 장치의 한쪽 끝으로 옮기는 것이다. 압축 후에는 하나의 커다란 공백이 생기게 된다. 윈도우 디스크 조각 모으기
21. 가상 기억 장치(보조 기억 장치) 다중 프로그래밍
- 보조 기억 장치를 주기억 장치처럼 사용하는 것으로, 주기억 장치보다 용량이 큰 프로그램도 처리가 가능하다.
- 프로그램을 여러 개의 작은 블록 단위로 나누어서 가상 기억 장치에 보관해 놓고 프로그램 실행 시 요구되는 블록만 주기억 장치에 불연속적으로 할당하여 처리한다.
- 사용자 프로그램이 실제 기억 장치보다 커도 수행이 가능하다.
- 주기억 장치의 물리적 공간보다 큰 프로그램이 실행될 수 있다.
- 프로그램 실행 시 주소 변환 작업이 필요하기 대문에 설계가 복잡해 진다.
- 프로그램 크기를 줄이지 않고 순차적으로 수행하는 기법인 오버레이(Overlay) 문제는 자동적으로 해결된다.
- 연속 할당 방식에서의기억 장치 단편화 문제를 적극적으로 해결할 수 있다.
- 기억 장치의 이용률과 다중 프로그래밍의 효율을 높일 수 있다.
- 프로세스가 갖는 가상 주소 공간상의 연속적인 주소가 실제 기억장치에서도 연속적일 필요는 없다.
- 가상 기억 장치의 일반적인 구현 방법은 고정 분할 기법(페이징 기법)과 가변 분할 기법(세그멘테이션 기법)이 있다.
- 프로그램을 주기억 장치에 적당한 크기로 분할하여 당장 필요한 것만 우선 주기억 장치에 상주시키고 실행하면서 디스크에 존재하는 분할된 프로그램 일부와 주기억 장치에 이미 상주된 프로그램 일부의 교체 작업을 반복하면서 프로그램을 실행하는 방법이다.21-1. 고정 분할(정적 분할, Page, Paging)
- 주기억 장치와 프로그램의 크기를 고정으로 분할하는데 그 크기가 모두 같다는 것이다.
- 디스크에 존재하는 분할된 프로그램, 즉 페이지와 주기억 장치에 분할된 영역과 페이지가 분할되면서 프로그램이 실행되는데 이러한 기술을 보통 페이지 기법 혹은 페이징(Paging)이라고 한다.
- 프로그램의 크기에 제한이 없으며 주기억 장치를 효율적으로 사용할 수 있다는 것이다.
- 외부 단편화는 존재하지 않지만 내부 단편화가 발생한다. 내부 단편화의 발생 빈도는 매우 낮다.
- 외부 단편화는 존재하지 않으며, 내부 단편화는 최소화할 수 있다.
- 항상 같은 크기로 분할하는 것은 크기가 일정하지 않은 모듈화 프로그램에 사용하기에는 적당하지 않다.
- 프로그램을 여러 개의 다른 크기로 분할하고 주기억 장치에서는 분할된 크기에 맞게 동적으로 분할하여 적재시키는 방식이다.
- 크기가 다른 모듈을 고정된 길이를 같는 페이지로 구분하여 사용할 경우, 고정된 페이지의 크기보다 작거나 큰 모듈은 주기억 장치에서 사용하지 않는 부분이 많이 발생될 것이다. 이로 인한 메모리 효율과 전체적인 성능은 떨어지게 된다.
- 외부 단편화만 발생한다.
- 프로그램을 세그먼트화하는 근본적인 이유는 메모리 절약을 위해서이다.
- 세그먼트 기법에서는 기억 장치 보호 카(Storage Protection Key)가 필요하다.
- 세그먼트 기법에서 빈 공간이 생기는 현상을 체커 보딩(Checker-boarding)이라고 한다.
- 각 프로그램은 분할된 자신만의 영역이 없으므로 다른 프로그램의 세그먼트들은 같은 기억 공간을 공유한다.
22. 가상 기억 장치 주요 기술
- 22-1. 오버레이(Overlay)
- 단일 사용자 시스템에서 프로그램의 크기가 주기억 장치의 용량보다 클 수는 없다.
- 더 이상 사용하지 않는 프로그램을 보조 기억 장치로 옮긴 후 그 기억 공간을 다른 프로그램이 사용하게 되면 실제 영역보다 더 큰 프로그램을 실행할 수 있다.
- 실행되어야 할 작업의 크기가 커서 사용자 기억 공간에 수용될 수 없을 때 작업의 모든 부분들이 동시에 주기억 장치에 상주해 있을 필요가 없다.
- 작업을 분할하여 필요한 부분만 교체하여 실행할 수 있다.
- 가상 기억 장치 시스템에서 가상 페이지 주소를 사용하여 데이터를 접근하는 프로그램이 실행될 때, 프로그램에서 접근하려고 하는 페이지가 주기억 장치에 있지 않은 경우 발생하는 현상이다.
- 페이지 폴트 처리 순서
- 실행하고자 하는 페이지가 주기억 장치 내에 존재하지 않는 경우 운영체제에서 트랩(Trap)을 요청한다.
- 운영체제는 현재 진행 중인 사용자 레지스트리와 프로그램 상태를 저장한다.
- 현재 사용 가능한(교체 가능한) 페이지를 페이지 사상 테이블에서 찾는다.
- 가상 기억 장치에 존재하는 해당 페이지를 주기억 장치로 가져온다.(Backing Store에 있는 페이지를 물리적 메모리로 가져온다.)
- 페이지 사상 테이블을 조정한다.
- 프로그램 실행(명령어 수행)을 계속한다.
- 동시에 여러 개의 작업이 수행되는 다중 프로그래밍 시스템 또는 가상 기억 장치를 사용하는 시스템에서 하나의 프로세스가 작업 수행 과정 중 지나치게 페이지 폴트가 발생함으로써 전체 시스템의 성능이 저하되는 현상이다.
- 스래싱 현상의 방지 방법
- 다중 프로그래밍의 정도를 낮춘다.(동시에 실행되는 프로그램의 수를 줄인다.)
- CPU 이용률을 높인다.
- 페이지 폴트율을 조절하여 대처한다.
- 자주 사용하는 페이지들을 주기억 장치에 미리 갖다 놓는다.(Working Set)
- 프로그램이 실행할 때 기억 장치 내의 모든 정보를 균일하게 참조하는 것이 아니라 어느 한 순간에 특정 부문을 집중적으로 참조하는 프로그램의 순차적인 성질이다.
- 한번 호출된 자료나 명령은 곧바로 다시 사용될 가능성을 말한다.
- 디스크로부터 주기억 장치에 읽어들을 수 있는 블록(물리적 레코드)의 크기로 여러 개의 페이지를 주기억 장치에 가져올 수 있다.
- 시간 구역성(Temporal), 공간 구역성(Spatial)이 있다.
- 시간 구역성(Temporal)
- 최근에 참조된 기억 장소가 가까운 미래에도 계속 참조될 가능성이 높다.
- Looping, Subroutine, stack, Counting, Totaling 변수들
- 공간 구역성(Spatial)
- 하나의 기억 장소가 참조되면 그 근처의 기억 장소가 계속 참조될 가능성이 높다.
- 배열 순회, 프로그램의 순차적 코드 실행, 프로그램에서 관련된 변수들을 서로 근처에 선언하는 경우
- 프로그램의 움직임에 대한 모델
- 프로세스를 효과적으로 실행하기 위해서는 주기억 장치에 유지되어야 하는 페이지들의 집합
- 자주 참조되는 페이지의 집합은 주기억 장치에 미리 적재해두면 페이지 폴트를 최소화할수 있고 효율적인 실행이 가능하다.
23. 반입(Fetch) 전략
- 프로그램/데이터를 주기억 장치로 가져오는 시기를 가져오는 전략 -> When23-1. 요구(Demand) 반입
- 요구가 있을 때마다 주기억 장치로 옮기는 방법이다.
- 응용 프로그램을 실행하는 것은 사용자의 요구에 의해 주기억 장치에 적재하는 것이다.
- 앞으로 요구될 가능성이 큰 데이터 또는 프로그램을 예상하여 주기억 장치로 미리 옮기는 방법이다.
- 가상 기억 장치를 사용하게 될 때 주로 사용한다.
- 자주 사용하는 페이지는 미리 주기억 장치에 가져다 놓는다. -> Working Set
- 앞으로 사용할 가능성이 높은 페이지를 가져다 놓는다. ->Locality
- 예상이 성공하면 프로그램의 실행 속도가 빨라지지만, 실패하면 오버헤드가 발생한다.
24. 배치 전략
- 주기억 장치에 프로그램/데이터의 위치를 정하는 전략 -> where24-1. 최초 적합(First Fit)
- 입력된 작업을 주기억 장치 내에서 그 작업을 수용할 수 있는 첫 번째 공백에 배치한다.
- 주기억 장치 내의 여러 공백 중 프로세스 배치가 가능한 첫 번째 공백을 선택하여 배치한다.
- 주기억 장치의 배치 전략 중 작업의 배치 결정을 가장 빨리 내릴 수 있는 방식이다.
- 내부 단편화의 크기에 상관없이 단편화가 많이 발생한다.
- 초기 결정력이 가장 빠르다.
- 입력된 작업을 주기억 장치 내의 공백 중에서 그 작업에 가장 잘 맞는 공백에 배치시킨다.
- 주기억 장치 내의 여러 공백에 대해서 프로세스 크기를 차감하여 그 결과값이 가장 작은 공백에 프로세스를 배치한다.
- 내부 단편화가 가장 적게 발생한다.
- 검색 시간이 길어 결정력이 가장 느리다.
- 입력된 작업을 주기억 장치 내에서 가장 잘 맞지 않는 공백, 즉 가장 큰 공백에 배치한다.
- 내부 단편화가 가장 크게 생긴 공백에 배치한다.
- 주기억 장치 내의 여러 공백 각각에 대해서 프로세스 크기를 차감하여 그 결과값이 가장 큰 공백에 프로세스를 배치한다.
25. 교체(재배치 전략)
- 주기억 장치 내의 빈 공간 확보를 위해 제거할 프로그램/데이터를 선택하는 전략 -> How, What25-1. OPT(OPTimal Replacement, 최적)
- 페이지 사용 횟수를 정확히 예측하여 교체하는 방법이다.
- 앞으로 가장 오랫동안 사용되지 않을 페이지와 교체한다.
- 가장 이상적이지만 실현 가능성이 희박하다.(앞으로 사용될 페이지를 미리 알 수는 없기 때문이다.)
- 페이지 폴트 횟수가 가장 적으므로 성공(hit)률이 가장 크다.
- 주기억 장치 내에 가장 오래된 페이지와 교체한다.
- 알고리즘이 가장 간단하다.
- 페이지 교체가 가장 많다.(페이지 폴트가 가장 많이 발생한다.)
- 프로세스에 할당된 페이지 프레임 수가 증가하면 페이지 부재의 수가 감소하는 것이 당연하지만 페이지 프레임 수가 증가할 때, 현실적으로 페이지 부재가 더 증가하는 모순(Anomaly) 현상이 발생한다.
- 참조된지 가장 오래된 페이지를 대체 대상으로 선정한다.
- 현시점에서 가장 오랫동안 사용하지 않은 페이지와 교체한다.
- 각 페이지마다 계수기(시간 기억 영역)을 두어 사용하는 기법이다.
- 페이지별로 사용(참조)된 횟수를 기억할 참조 변수를 확보한 후에 페이지가 참조될 때마다 1씩 증가한다. 주기억 장치에 기억된 페이지 중 하나를 교체(Swap)하려고 할 때 참조 변수에 기억된 값이 가장 적은 페이지를 교체 대상으로 선정하는 기법이다.
- 사용한(참조된) 횟수가 가장 적은 페이지와 교체한다.
- 사용한 횟수가 기억될 참조 변수를 각 페이지에 두어 사용한다.
- 페이지당 두 개의 정보 비트(참조 비트, 변형 비트)를 이용하여 교체하는 방법이다.
- 최근에 사용(참조)하지 않은 페이지를 제거한다.
- 하드웨어 비트 - 참조 비트(Referenced Bit)와 변형 비트(Modified Bit)를 사용한다.
- 참조 비트 = 언제 호출, 변형 비트 = 언제 사용
- 자주 사용(참조)하는 페이지들은 주기억 장치에 미리 적재하여 페이지 폴트가 최소가 되도록 해야 한다.
- Working Set에 존재하는 페이지들을 관찰하여 최근에 자주 사용되고 있지 않은 페이지와 Working Set에 속하지 않은 페이지 중에 최근에 자주 사용하는 페이지와 교체하여 교체 효율을 높이는 방법이다.
- 가장 오래된 페이지를 제거하기 전에 기회를 한번 더 준다.
- FIFO 순으로 유지시키면서 LRU 근사 알고리즘처럼 참조 비트를 갖게 한다.
- 가장 오래된 페이지를 다시 처음에 입력된 페이지로 되돌리기 위해선 LRU의 계수기를 필요로 하게 된다.
26. 디스크
- 트랙 : 디스크의 회전축을 중심으로 데이터가 기록되는 동심원, 디스크의 종류마다 개수가 모두 다르다.
- 섹터 : 하나의 트랙을 몇 개로 분할한 블록으로 한 개의 섹터는 보통 512 ~ 1024 바이트를 기록할 수 있다. 데이터를 기록하는 단위를 클러스터(Cluster)라고 하며 1개 또는 여러 개의 섹터로 구성된다.
- IPL(Initial Program Loader) : 디스크 드라이브가 디스크에 접근할 때 디스크의 물리적인 정보를 제공하는 것, 부트 섹터
- FAT(File Allocation Table) : 사용자가 해당 블록(클러스터)의 포인트(위치 정보)를 실수로 지워지게 하는 것을 예방하고 블록 접근을 빠르게 하기 위해 포인터를 모아 놓은 곳, 1대1로 사상한 정보들을 가지고 있다. 2개 이상의 복사본을 가지고 있다.
- 디렉터리 : 디스크에 저장된 파일의 기본적인 정보를 수록하는 공간. 파일명, 파일 속성, 작성 날짜, 작성 시간, 파일 위치, 파일의 크기 등을 정보로 가진다.
- Seek Time(탐색 시간) : 디스크 상의 원하는 데이터를 엑세스하기 위해 트랙 또는 실린더에 헤드를 위치시키는데 걸리는 시간
- Latency Time, Rotational Delay, RPM 지연시간, 회전 지연 시간 : 지정된 트랙에 위치한 헤드가 원하는 섹터에 도달하는데 걸리는 시간이다.
- Transmission Time(전송 시간) : 디스크로부터 주기억 장치로 데이터가 이동하는 시간이다.
27. 디스크 스케줄링
- 디스크에 존재하는 파일의 데이터들은 연속되지 않은 많은 섹터에 저장되어 있다. 물리적으로 회전하는 디스크에서 어떻게 하면 신속하게 많은 양의 데이터를 가져오느냐를 고민
- 처리량을 최대화한다.
- 응답 시간을 최소화한다.
- 응답 시간의 편차를 최소화한다.
- 입출력 채널이 복잡하면 그 채널에 부착된 제어 장치를 분산 배치한다.
- 제어 장치가 포화 상태가 되면 해당 제어 장치에 부착된 디스크의 수를 감소시킨다.
- 입출력 채널이 복잡하면 채널을 추가한다.27-1. FCFS(First Come First Served, FIFO)
- 현재 헤드에서 가장 가까운 입출력 요청을 먼저 서비스한다.
- 헤드의 탐색 거리가 가장 짧은 요청을 먼저 서비스하게 된다.
- 가운데 트랙이 가장자리보다 서비스 받을 확률이 높다.
- 헤드에서 멀리 떨어진 요청은 기아 상태가 발생할 수 있다.
- 일괄 처리에 유용
- 대화형에는 부적합
- 헤드가 디스크 표면을 안쪽/바깥쪽으로 이동하면서 I/O 요청을 서비스한다.
- 헤드는 이동하는 방향의 앞쪽에 I/O 요청이 없을 경우에만 후퇴가 가능하다.
- 진행 뱡상의 가장 짧은 거리에 있는 요청을 먼저 수행한다.
- 진행 방향으로 끝까지 진행한다.
- 차별 대우를 최소화하고 응답 시간의 편차를 줄인다.
- 대부분의 디스크 스케줄링 기본 전략이다.
- 항상 바깥쪽 실런더(트랙)에서 안쪽으로 움직이면서 가장 짧은 탐색 시간을 가진 요청을 우선 서비스 한다.
- 헤드는 트랙의 안쪽으로 한방향으로만 움직이면서 안쪽에 더 이상 I/O 요청이 없으면 다시 바깥쪽에서 안쪽으로 이동하면서 I/O 요청을 서비스하게 된다.
- 부하가 많은 경우 좋다.
- SCAN, C-SCAN을 보완
- 진행 방향이 더이상 요청이 없다면 방향을 바꾼다.
- 어떤 방향의 진행이 시작될 당시 대기 중이던 요청들만 서비스하고, 진행 도중 도착한 요청들은 한데 모아져서 다음 진행 때 최적으로 서비스할 수 있도록 배열된다.
- 부하가 매우 큰 항공 예약 시스템을 위해 개발
- 헤드는 C-SCAN 처럼 움직이며 예외적으로 모든 실린더는 그 실린더에 요청이 있거나 없어도 전체 트랙이 한 바퀴 회전할 동안의 서비스를 받는다.
- 거의 사용하지 않는다.
- 탐색 시간과 회전 지연 시간을 줄이는 스케줄링
- 27-2. SSTF(Shortest Seek Time First)
28. 파일의 구조
- 파일 시스템이 사용하는 파일 기록 방식28-1. 순차 접근 파일(Sequential Access File)
- 입력되는 데이터의 논리적인 순서에 따라 물리적으로 연속적인 위치에 기록하는 파일 방식
- 저장 매체의 효율이 매우 높다.
- 물리적으로 연속적인 저장이 되기 때문에 Access 시간이 가장 빠르다.
- 특정한 데이터를 검색하는데 비교 횟수가 많아지므로 Seek(검색) 시간이 느리다.
- 저장 정보를 따로 구성하지 않아도 되므로 공간의 낭비가 없다.
- 구현이 쉽기 때문에 어떤 매체라도 쉽게 사용할 수 있다.
- 일괄 처리에 접합하다.
- 테이프를 모형화한 것이다.
- 데이터 내의 키 필드(Key Field)를 해싱 사상 함수에 의해 물리적인 주소로 변환하여 데이터를 기록하거나 검색하는 방식의 파일이다.
- DASD(Direct Access Storage Device)의 물리적 주소를 통하여 직접 액세스 된다.
- 특정 레코드를 검색하기 위하여 Key와 보조 기억 장치 사이의 물리적인 주소로 변환할 수 있는 사상 함수(Mapping Function)가 필요하다.
- 해싱 사상 함수를 사용하므로 검색 속도가 가장 빠르다.
- 한번 파일을 개방하면 읽거나 쓰기를 자유롭게 할 수 있다.
- 어떤 레코드라도 평균 접근 시간 내에 접근할 수 있다.
- 키 변환법에 따라 공간의 낭비를 가져올 수 있다.
- 디스크 기억 장치에 많이 사용된다.
- 순차 파일과 직접 파일에서 지원하는 편성 방법이 결합된 형태로 순차 처리와 직접 처리가 모두 가능하다.
- 디스크 기억 장치에 많이 이용된다.
- 각 레코드는 레코드 키 값에 따라 논리적으로 배열된다.
- 시스템은 각 레코드의 실제 주소가 저장된 인덱스를 관리한다.
- 융통성이 매우 뛰어나다.
- 레코드를 추가 및 삽입하는 경우 파일 전체를 복사할 필요가 없다.
- 실제 데이터 처리 외에 인덱스를 처리하는 추가적인 시간이 소모되므로 파일 처리 속도가 느리다.
- 인덱스를 저장하기 위한 공간과 오버플로 처리를 위한 별도의 공간이 필요하므로 기억 공간의 낭비가 있다.
- 파일을 구성하는 블록의 번호는 절대 블록 번호여야 사용자가 자신의 파일이 아닌 부분에 접근하는 것을 방지할 수 있다.
- 삽입, 삭제가 많아지면 파일에 대한 재편성이 이루어져야 한다.
- Master Index : Cylinder Index 구역의 인덱스
- Cylinder Index : Track Index 구역의 인덱스
- Track Index : 기본 데이터 구역의 인덱스
- 하나의 파일을 여러 개의 파일로 재구성한 파일이다.
- 분할된 파일은 여러 개의 순차 서브 파일로 구성된 파일이다.
- 파일의 크기가 큰 경우에 사용한다.
- 하드 디스크를 플로피 디스크에 저장할 때 사용한다.
29. 파일의 디스크 공간 할당
- 파일의 데이터를 디스크에 물리적으로 저장하고 삭제하는 방법을 말한다.29-1. 연속 블록 할당(Contiguous Block Allocation)
- 데이터를 물리적, 연속적으로 저장한다.
- 데이터를 저장할 크기를 미리 지정해야 한다.
- 파일마다 크기가 다르고 추가, 삭제가 빈번히 발생할 경우에 단편화 현상이 많이 발생한다.
- 디스크 활용을 최대화하기 위한 통합(Coalecing), 집약(Compaction, garbage Collection)이 필요하다.
- 파일의 크기보다 큰 연속 공간이 없을경우에는 파일을 생성할 수 없다.
- 가상 기억 장치를 응용하여 사용할 수 없다.
- 용적률이 줄어든다.
- 액세스 시간이 감소한다.
- 디렉터리 구현이 쉽다.
- 디스크 공간을 일정한 길이를 갖는 단위(섹터, 블록)로 나누어 할당하는 기법이다.
- 분할된 영역은 독립적으로 취급되며 파일의 데이터들은 불할된 영역에 순차적, 분산적으로 저장할 수 있는 방법이다.
- 분할 저장된 파일의 각 데이터들은 파일 Open시에 연결된 정보를 이용해 사용된다.
- 실제 데이터를 저장하는 공간 외에 분할된 정보와 파일의 연결된 데이터 정보를 저정해야 하는 영역이 필요하므로 부가적인 저장 공간이 연속 블록 할당에 비해 많이 사용된다.
- 파일의 크기에 해당되는 디스크 공간을 미리 지정해 주지 않아도 된다.
- 단편화를 줄일 수 있다.
- 디스크 압축(집약)이 불필요하다.
- 파일의 크기보다 큰 연속 공간이 없을 경우라도 파일을 생성할 수 있다.
- 가상 기억 장치를 응용하여 사용할 수 있다.
- 용적률이 좋아진다.
- 액세스 시간이 증가한다.
- 디렉터리 구현이 어렵다.
- 섹터 단위형 : 디스크 섹터 단위로 파일의 데이터가 분산되어 저장된다.
- 각 섹터는 연결 리스트 구조 형태로 연결된다.
- 파일의 크기가 커지면 비어 있는 섹터를 사용하고 작아지면 사용하지 않은 섹터를 반납한다.
- 블록 단위형
- 블록 체인 기법 : 여러 개의 섹터를 묶은 블록을 체인처럼 연결한 방법
- 인덱스 블록 체인 기법 : 인덱스에 블록의 주소를 링크시켜 사용한다. (Unix)
- 블록 단위 파일 사상 기법 : 파일 정보의 해당 블록을 사상시켜 연결하여 사용한다. (MS-DOS, MS-Windows)
30. 디렉터리
- 파일 시스템 내부에 있는 기능으로 디스크 내에 존재하는 많은 파일을 쉽게 사용할 수 있도록 조직화된 기법이다.30-1. 1단계 디렉터리
- 가장 간단한 디렉터리이다.
- 디렉터리 시스템에 보관된 모든 파일의 정보를 포함해야 한다.
- 파일이 같은 디렉터리 내에 있어야 하므로 유일한 파일명으로 작성해야 한다.
- 파일명의 길이를 제한한다.
- 중앙에 마스터 디렉터리가 존재하고 그 아래 사용자 디렉터리가 있는 구조다.
- 다른 사용자와의 파일 공유가 어렵다.(다른 사용자의 디렉터리 안에 파일들을 검색할 수 없으므로 공유가 어렵다.)
- 파일명의 길이가 길어 사용하기 매우 어렵다.(파일명뿐만 아니라 사용자 디렉터리명을 같이 지정해야 한다.)
- 2단계 이상으로 깊어지면 트리 구조 디렉터리가 된다.
- 하나의 루트 디렉터리와 여러 개의 부 디렉터리로 구성된다.
- 부 디렉터리는 그 하위로 또 다른 디렉터리를 구성할 수 있다.
- 각 디렉터리의 생성과 파괴가 용이하다.
- 동일한 이름의 여러 디렉터리 생성이 가능하다.
- Unix, MS-DOS, MS-Windows에서 사용한다.
- 트리 구조와 유사하다.
- 사이클을 허용하지 않는다.
- 하나의 파일이나 디렉터리를 상위 드렉터리에 공용할 수 있다.
- 링크 수만큼 파일을 공유하고 있으며 링크 수가 0이면 완전히 제거할 수 있다.
- 하나의 파일을 여러 사용자가 공유하기 때문에 삭제 시 문제점이 많이 발생한다.
- 융통성이 있으며 기억 공간을 절약할 수 있으나 복잡하다.
- 공용된 파일이나 디렉터리는 물리적으로 한 개만 존재한다.
- 하나의 파일이 다수의 이름으로 존재할 수 있다.
- 공유하고 있는 파일 제거 시 Dangling Pointer가 발생할 수 있다.
- Unix에서 사용한다.
- 그래프 탐색 알고리즘이 간단하다.
- 사이클을 인정하므로 파일 접근이 용이하다.
- 하나의 파일이나 디렉터리를 상위 디렉터리에 공용할 수 있다.
- 상위 파일이나 디렉터리를 자신의 파일이나 하위 디렉터리로 구성할 수 있다.
- 파일을 제거하기 위한 Garbage-Collection(자투리 제거기)을 위한 참조 계수기가 필요하다.

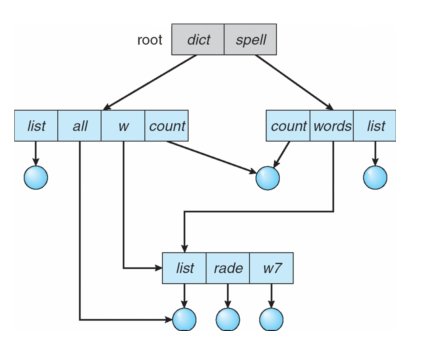



31. 자원 보호 기법
- 자원 보호 기법은 컴퓨터 시스템에서 보호되어야 할 모든 대상의 접근 목록을 두어 접근 가능한 사용자와 가능한 동작을 기록한 후, 이를 근거로 접근을 허용하다는 기법31-1. Access Control Matrix(접근 제어 행렬)
- 객체의 사용 권한을 모든 사용자 리스트와 함께 표시하는 행렬
- 임의의 사용자가 허용되지 않은 자원에 접근하지 못하도록 한다.
- 사용자가 많게 되면 공간 낭비가 많아 호율이 떨어진다.
- 시스템 관리자는 모든 자원을 제어할 수 있는 권한을 갖고 있다.
- 객체와 그 객체에 허용된 조작 리스트
- 영역과 결합되어 있으나 사용자에 의해 간접적으로 엑세스되는 기법
- 접근 제어 행렬에서 허용되지 않은 사용자는 제외한다.
- 보호하려는 대상에 영역별로 접근 권한을 구성하여 사용한다.
- 접근 행렬의 열을 하나의 리스트로 묶어 놓는 것이다.
- 권한이 없는 셀을 위한 메모리를 낭비할 필요가 없어지므로 효율적으로 사용할 수 있다.
- 사용자 개개인에 허용된 조작 리스트로 사용자가 시스템에 접근하면 사용자의 권한을 파악하게 된다.
- 접근 제어 행렬에서 수평으로 있는 각 행만을 따온 것으로서 영역에 대한 권한은 객체와 그 객체에 허용된 연산자로 구성되어 있다.


32. 비밀키와 공개키
- 암호화 기법으로 암호화 되기 전을 플레인 텍스트(Plain Text), 암호화 되고 난 후를 사이퍼 텍스트(Cipher Text)32-1. 비밀키, 공통키, 대칭형 암호화 알고리즘(Private Key System)
- 암호화 키와 복호화 키는 같은 키이다.
- 해독키의 비밀성은 보장되어야 한다.
- 정보를 교환하고 있는 사람들끼리만 비밀키를 사용해야 하므로 키 분배가 어렵다.
- 디지털 서명이 어렵다.
- 평문을 암호화하는데 가장 많이 사용한다.
- 대칭키, 관용키, 단일키, 비밀키, 공통키
- DES, IDEA, RC2 등으로 복호화 한다.
- 대체 기법 : 어떤 알고리즘이나 추측에 의해서 알아맞힐 수 없는 특수한 암호키를 가지고 데이터를 암호화했다가 자료 이용 시 같은 암호키를 이용하여 해독하는 기법
- DES(Data Encryption Standard) : 미국 상무국 표준 협의에서 공모하여 사용하고 있는 암호화 기법으로, 56비트의 암호/복호키를 이용하여 64비트의 평문을 암호화 또는 복호화하는 기법
- 계산속도가 빠르다
- 많은 암호화 통신에서는 비밀 키 암호를 사용하여 대칭 키 암호의 공통키를 공유하고, 그 키를 기반으로 실제 통신을 암호화하는 구조를 사용한다.
- 암호화 키와 복호화 키는 다른 키를 사용한다.
- 공개키(암호화 키)는 공개되지만, 비밀키(복호화 키)는 보호되어야 한다.
- 키 분배는 공통 키 분배보다 비교적 간단하다.
- 디지털 서명에 적당하다.
- 암호화 과정이 복잡하여 속도가 느리다.
- 비대칭키, 공용키
- RSA, PGP 등 암호 방식이 있다.
- RSA : 데이터를 암호문으로 변환할 때 암호키와 암호문을 평문으로 변환시킬 때 복호키가 서로 다르며 암호화하는 암호키는 공개하고 복호키는 비밀로 해 데이터의 송수신 시 보안을 유지하는 방법
- 공개 키와 비밀 키가 존재, 공개 키는 누구나 알 수 있지만 그에 대응하는 비밀 키는 소유자만 알 수 있어야 한다.
- 공개 키 암호 : 특정한 비밀 키를 가지고 있는 사용자만 내용을 열어볼 수 있다.
- 공개 키 서명 : 특정한 비밀 키로 만들었다는 것을 누구나 확인 할 수 있다.
- 개인키로 암호화한 정보는 그 쌍이 되는 공개키로만 복호화 가능하고, 반대로 공개키로 암호화 한 정보는 그 쌍이 되는 개인키로만 복호화가 가능하다.
33. MIMD(Multiple Instruction Multiple Data)
- 다중 처리기 컴퓨터
- 한번에 여러 개의 명령어를 처리한다.
- 여러 명의 사용자가 여러 개의 CPU를 사용한다.33-1. 다중 처리기(Multi processor)
- 여러 개의 CPU가 하나의 메모리를 공유하는 형태
- CPU 끼리의 결합력이 강하다.
- 병렬 처리에 적합한 컴퓨터 시스템 구조이다.
- 전송 지연이 짧고 데이터 처리율이 높다.
- 프로세스 간 통신은 공유 메모리를 통해 이루어진다.
- 공유 메모리를 차지하려는 프로세스 간의 경쟁이 발생한다.
- 기억 장소가 하나이므로 운영체제도 종속적으로 사용된다.
- 모든 CPU는 하나의 운영체제에서 통제되는 대칭적인 구조이다.
- 여러개의 CPU가 자신만의 독립적인 메모리를 사용하는 형태
- CPU끼리 결합력이 약하다.
- 분산 처리에 적합한 컴퓨터 구조이다.
- 전송 지연이 길고 데이터 처리율이 낮다.
- 프로세스간 통신은 통신망에 메시지(소켓 : Socket) 전달로 통신할 수 있다.
- 구성 요소(컴퓨터, 주변 장치 등)의 추가 또는 삭제가 용이하다.
- 기억 장소가 CPU와 독립적으로 사용되므로 운영체제도 독립적으로 사용된다.
- 각 시스템은 자신만의 운영체제를 갖는 분리 수행 구조이다.

34. 주-종(Master/Slave) 프로세서 구조
- 하나의 컴퓨터 시스템에 두 개의 프로세서(처리기, CPU)가 있을 경우 입출력과 연산을 각각 독립적으로 수행하지 않고 주 프로세서는 입출력과 연산, 종 프로세서는 연산을 일부 담당하게 된다.
- 주 프로세서가 중단되면 시스템은 멈추지만, 종 프로세서가 중단되면 컴퓨터 시스템은 계속 동작한다.
- Master CPU는 입출력과 연산을 담당한다.
- Slave CPU는 연산만을 담당한다.
- 주 프로세서만 운영체제를 수행한다.
- 종 프로세서는 사용자 프로그램만을 수행한다.
- 종 프로세서에게 입출력 발생 시 주 프로세서에게 서비스를 요청한다.
- 프로세서가 비대칭 구조이다.
35. 분산 운영체제(Distributed OS)
- 전체 네트워크에 공통적으로 단일 운영체제가 실행되는 시스템으로 원격에 있는 자원을 마치 전역 자원인 것처럼 쉽게 접근하여 사용할 수 있는 방식이다.35-1. 목적
- 자원 공유의 증대성 : 각 시스템이 통신망을 통해 연결되어 있으므로 유용한 자원을 공유하여 사용할 수 있다.
- 계산 속도의 향상 : 하나의 일을 여러 시스템에 분산하여 처리하기 때문에 연산 속도가 향상된다.
- 신뢰성 향상 : 하나의 시스템에 오류가 발생하더라도, 다른 시스템은 계속 작업을 수행할 수 있기 때문에 신뢰도가 향상된다.
- 컴퓨터 통신 : 지리적으로 멀리 떨어진 시스템에 통신망을 두어 정보를 교환할 수 있다.
- CPU의 처리 능력 한계를 극복할 수 있다.
- CPU의 처리 능력을 높이려면 현재 가격의 제곱만큼 비싸다. 처리 속도가 낮은 여러 개의 CPU를 연결하여 처리 속도를 향상시킬 수 있기 때문에 경제적이다.
- 반응 시간이 빠르면 계산 능력, 처리량, 신뢰성, 가용성은 모두 향상된다.
- 특정한 시스템의 병목 현상을 제거하기 위해 필요한 자원을 추가할 수 있으므로 확장성이 좋다.
- 부하를 균등하게 배분할 수 있어 처리 효율이 샹상된다.
- 다수의 사용자가 데이터를 공유할 수 있으며, 통신이 용이하다.
- 여러 개의 컴퓨터 시스템이 연결되어 있으므로 보안이 매우 취약하다.
- 여러 개의 컴퓨터를 하나의 컴퓨터처럼 운영해야 하므로 소프트웨어 개발이 매우 어렵다.
- 적응성이 하나의 CPU를 사용할 때보다는 떨어진다.
- 에러 발생 시 원이 파악이 어렵다.
- 링크 결함 : 두 개의 사이트(컴퓨터, 노드, 교환기) 간에 연결이 잘못되어 발생하는 결함
- 사이트 결함 : 사이트 자체에서 발생할 수 있는 결함이다.
- 메시지 분실 : 통신 회선을 통해 해당 사이트로 메시지가 전달되는 과정에서 시간 지연이나 다른 이유로 메시지를 잃어버리는 결함이다.
- 성형 연결(Star Connected) 구조
- 환형 연결(Ring Connected) 구조
- 다중 접근 버스 연결(Multi access bus Connected) 구조
- 완전 연결(Fully Connected) 구조
- 부분 연결(Partially Connected) 구조
- 계층 연결(Hierarchy Connected) 구조
36. 투명성(Transparency)
- 사용자가 분산된 여러 자원의 위치 정보를 알지 못하고 마치 하나의 커다란 컴퓨터 시스템을 사용하는 것 처럼 인식하도록 설계
- 위치 투명성 : 사용자가 원하는 파일이나 데이터 베이스, 프린터 등의 자원들이 지역 컴퓨터 또는 네트워크 내의 다른 원격지 컴퓨터에 위치하더라도 위치에 관계없이 그의 사용을 보장한다.
- 이주 투명성 : 자원들을 이동하여도 사용자는 자원의 이름이나 위치를 고려할 필요가 없다.
- 복제 투명성 : 사용자에게 통보 없이 파일들과 자원들의 부가적인 복사를 자유롭게 할 수 있다.
- 병행 투명성 : 사용자들이 자원을 자동으로 공유할 수 있다.
- 병렬 투명성 : 몇 개의 처리기가 사용되는지 알 필요가 없다.
37. 스레드(Thread)
- 운영체제에서는 스레드를 실행될 명령어들의 연속
- 프로세스에서는 명령어들이 순차적으로 실행되기 때문에 실행 스레드라고 할 수 있다.
- 단일 스레드 : 하나의 프로세스를 수행하는 과정에서 여러 개의 인터럽트 루틴이나 함수를 순서적으로 수행하는 프로세스
- 다중 스레드 : 하나의 프로세스에 여러 개의 스레드가 존재한다.
- 스레드는 순차적 실행과 프로세스 상태 전이의 병렬성을 접속하기 위해 개발되었다.
- 다중 프로그래밍 기법에서 여러 개의 프로세스는 하나의 시스템을 공유한다.
- 하나의 프로세스에 여러 개의 스레드가 실행 될 수 있도록 하는 기술이다.37-1. 장점
- 단일 프로세스를 다수의 스레드로 생성하여 병행성을 증진시킬 수 있다.
- 실행 환경을 공유시켜 기억 장소의 낭비가 줄어든다.
- 프로세스의 생성이나 문맥 교환 등의 오버헤드를 줄여 운영체제의 성능이 개선된다.
- 프로세스 내부에 포함되는 스레드는 공통적으로 접근 가능한 기억 장치를 통해 효율적으로 통신한다.
- 스레드를 사용하면 하드웨어, 운영체제의 성능과 응용 프로그램의 처리율을 향상시킬 수 있다.
- 하나의 프로세스에 여러 개의 스레드가 존재할 수 있다.
- 스레드는 동일 프로세스 환경에서 서로 독립적인 다중 수행이 가능하다.
- 스레드 기반 시스템에세 스레드는 독립적인 스케줄링의 최소 단위로서 프로세스의 역할을 담당한다.
- 생성된 프로세스가 자신을 생성한 프로세스의 텍스트와 데이터 영역을 그대로 공유하고 스택만 따로 갖는 새로운 모델이다.
- 응용 프로그램의 응답 시간을 감소시킬 수 있다.
- 프로세스 간의 통신 속도가 향상된다.
- 스레드 패키지를 사용자 영역에 두고 커널은 단일 프로세스를 관리한다.
- 스레드를 운영하지 않는 운영체제에서 실행할 수 있다.
- 이식성이 뛰어나다.
- 런 타임 시스템이 필요하다.
- 속도가 빠르다.
- 문맥 교환이 적다.
- 독자적 알고리즘이 필요하다.
- 대형 시스템에 적당하다.
- 구현이 어렵다.
- 커널을 스스로 호출하지 못한다.
- CPU 사용을 해제하지 못하면 시스템이 중단된다.
- 스레드 패키지를 커널 자체에서 운영 관리한다.
- 각 응용 프로그램들은 운영체제에 영향을 많이 받게 되므로 이식성이 낮다.
- 런 타임 시스템이 필요 없고 커널이 직접 한다.
- 속도가 느리다.
- 문맥 교환이 많다.
- 독자적 알고리즘이 필요없다.
- 대형 시스템에 부적당하다.
- 구현이 쉽다.
- 커널을 스스로 호출한다.
- CPU 사용을 해제하지 못하면 운영체제가 지원한다.
모든 내용의 권리는 2018 정보처리기사(영진 닷컴 출판사) 에 있습니다.
728x90
반응형
'OS' 카테고리의 다른 글
| [OS] 프로세스 간 통신(Inter-Process Communication,IPC) (0) | 2021.04.28 |
|---|---|
| [OS] 커널 수준의 쓰레드 vs 사용자 수준의 쓰레드 (0) | 2021.04.07 |
| [OS]인터럽트(interrupt) (0) | 2021.04.06 |
| [OS]context switching (0) | 2021.02.06 |
'OS' Related Articles
more



Comments