
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- MSA
- 자바
- OS
- Real MySQL
- 토비의 스프링 정리
- redis
- 자바 ORM 표준 JPA 프로그래밍
- 스프링
- Stream
- mysql
- thread
- JPA
- GC
- 이스티오
- 토비의 스프링
- jvm
- IntellJ
- gradle
- list
- Kotlin
- Stack
- 스트림
- spring
- 쿠버네티스
- SpringBoot
- Collection
- K8s
- 보조스트림
- 백준
- Java
- Today
- Total
인생을 코딩하다.
[Java] volatile 본문
volatile
volatile란?
- volatile 키워드는 java 변수를 Main Memory에 저장하겠다 라는 것을 명시한다.
- 매번 변수의 값을 읽을 때마다 CPU cache에 저장된 값이 아닌 Main Memory에서 읽는 것이다.
- 또한 변수의 값을 쓸 때마다 Main Memory까지 작성한다.
volatile를 쓰지 않았을 때, non-volatile일때의 문제점
멀티쓰레드 어플리케이션에서의 non-volatile 변수에 대한 작업은 성능상의 이유로 CPU 캐시를 이용한다. 둘 이상의 CPU가 탑제된 컴퓨터에서 어플리케이션을 실행한다면, 각 쓰레드는 변수를 각 CPU의 캐시로 복사하여 읽어들인다.
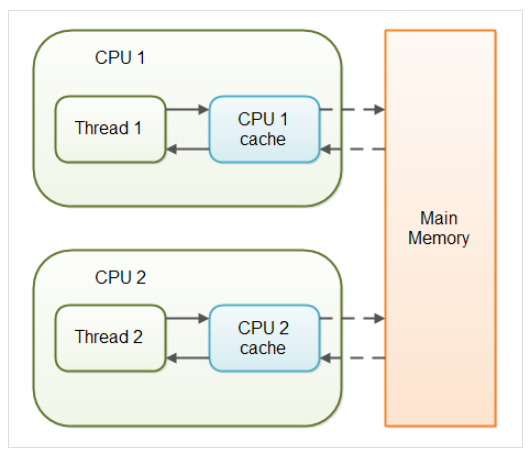
non-volatile 변수에 대한 작업은 JVM 이 메인 메모리로부터 CPU 캐시로 변수를 읽어들이거나, CPU 캐시로부터 메인 메모리에 데이터를 쓰거나 할 때에 대한 어떠한 보장도 하지 않는다.
- volatile 변수를 사용하고 있지 않는 MultiThread 어플리케이션에서는 Task를 수행하는 동안 성능 향상을 위해 Main Memory에서 읽은 변수 값을 CPU Cache에 저장하게 된다.
- 만약에 Multi Thread환경에서 Thread가 변수 값을 읽어올 때 각각의 CPU Cache에 저장된 값이 다르기 때문에 변수 값 불일치 문제가 발생하게 된다.
public class SharedObject {
public int counter = 0;
}둘 이상의 쓰레드가 다음과 같은 공유 객체로 접근하는 경우를 생각해보자.
Thread1 은 counter 변수를 증가시키고, Thread1 과 Thread2 가 때에 따라서 counter 변수를 읽는다.
만일 counter 변수에 volatile 키워드가 없다면, counter 변수가 언제 CPU 캐시에서 메인 메모리로 쓰일지(written) 보장할 수 없다. CPU 캐시의 counter 변수와 메인 메모리의 counter 변수가 다른 값을 가질 수 있다는 것이다.

쓰레드가 변경한 값이 메인 메모리에 저장되지 않아서 다른 쓰레드가 이 값을 볼 수 없는 상황을 '가시성' 문제라 한다. 한 쓰레드의 변경(update)이 다른 쓰레드에게 보이지 않는다.
counter 변수에 volatile 키워드를 선언한다면 이 변수에 대한 쓰기 작업은 즉각 메인 메모리로 이루어질 것이고, 읽기 작업 또한 메인 메모리로부터 다이렉트로 이루어질 것이다.
이러한 문제는 volatile 키워드를 추가함으로써 해결할 수 있다.
public class SharedObject {
public volatile int counter = 0;
}- volatile 키워드를 추가하게 되면 Main Memory에 저장하고 읽어오기 때문에 변수 값 불일치 문제를 해결 할 수 있다.
그러면 언제 volatile를 쓰는 것이 적절할까?
앞서 설명했듯, 두 쓰레드가 공유 변수에 읽기/쓰기 를 실행할 때, volatile 선언은 충분치 않다. 이런 상황에서는 변수값의 읽기/쓰기 명령의 원자성을 보장하기 위해 synchronized 를 써야한다. 변수를 읽고 쓸 때 volatile 선언은 변수에 접근하는 쓰레드들을 블록시키지 않는다. 이런 임계 영역에는 synchronized 키워드가 필요하다.
synchronized 블록을 대체하는 다른 것을 찾는다면, java.util.concurrent 패키지의 많은 원자성 데이터 타입들을 사용할 수도 있다. 에를 들자면 AtomicLong 이나 AtomicReference 와 같은 것들이다.
한 변수를 두고 오직 한 쓰레드만 이 변수에 읽기/쓰기 작업을 하고, 다른 쓰레드들은 읽기 작업만 하는 상황에서라면 이 때는 volatile 선언이 유효하다. 읽기 작업을 수행하는 쓰레드들은 언제나 이 변수의 가장 최근 수정된 값을 봐야하고, volatile 은 이를 보장해준다.
그리고 volatile 은 32비트와 64비트 변수에서 효과를 볼 수 있다.
(JVM에서 64비트 할당은 32비트 2번으로 이루어지기에 원자적이지 않다.)
참고 : junghyungil.tistory.com/126?category=892275
항상 volatile를 쓰는것이 옳을까?
volatile 선언이 변수의 읽기/쓰기 명령을 메인 메모리로부터 수행한다는 것을 보장한다고 할지라도, volatile 선언으로 해결할 수 없는 상황들은 여전히 남아있다.
위의 예제들 중, 공유 변수인 counter 가 있고 Thread1 만이 이 변수를 수정하고, Thread2 만이 이 변수를 읽는 이런 상황에서라면 volatile 선언이 변수의 가시성을 보장해준다. 멀티쓰레드 환경에서, volatile 공유 변수에 세팅된 새로운 값이 이 변수가 가지고 있던 이전의 값에 의존적이지 않는다면, 다수의 쓰레드들이 volatile 공유 변수를 수정하면서도 메인 메모리에 존재하는 정확한 값을 읽을 수 있다. 달리 말하자면, 만일 volatile 공유 변수를 수정하는 한 쓰레드가 이 변수의 다음 값을 알아내기 위해 이전의 값을 필요로 하지 않는다면 말이다.
하지만 아래 예제를 보자.
- Thread-1이 값을 읽어 1을 추가하는 연산을 진행합니다.
- 추가하는 연산을 했지만 아직 Main Memory에 반영되기 전 상황입니다.
- Thread-2이 값을 읽어 1을 추가하는 연산을 진행합니다.
- 추가하는 연산을 했지만 아직 Main Memory에 반영되기 전 상황입니다.
- 두 개의 Thread가 1을 추가하는 연산을 하여 최종결과가 2가 되어야 하는 상황이지만?
- 각각 결과를 Main Memory에 반영하게 된다면 1만 남는 상황이 발생하게 됩니다.

Thread1 과 Thread2 는 사실상 동기화에서 완전히 멀어진 상태이다. counter 변수의 실제 값은 2 가 되어야 하지만, 두 쓰레드는 각자의 값, 1 을 자신들의 캐시에 가지고 있다. 그리고 메인 메모리의 값은 아직 0 이다. 이 상황에서 쓰레드들이 캐시에 가진 변수의 값은 메인 메모리에 저장한다고 해도, counter 의 값은 1 이 된다. 잘못된 상황이다.
정리하자면,
- 하나의 Thread가 아닌 여러 Thread가 write하는 상황에서는 적합하지 않다.
- 여러 Thread가 write하는 상황이라면?
- synchronized를 통해 변수 read & write의 원자성(atomic)을 보장해야 한다.
volatile 성능에 어떤 영향이 있을까?
- volatile는 변수의 read와 write를 Main Memory에서 진행하게 된다.
- CPU Cache보다 Main Memory가 비용이 더 크기 때문에 변수 값 일치을 보장해야 하는 경우에만 volatile 사용하는 것이 좋다.
happends before guarantee
volatile 키워드는 "happends before guarantee" 성질을 갖는데, 이것은 volatile 변수에 대한 읽기/쓰기 명령은 JVM 에 의해 재정리되지 않음을 보장한다는 의미이다. volatile 변수에 대한 읽기/쓰기 명령을 기준으로, 이 변수 전에 존재하는 다른 명령들은 자기들끼리 얼마든지 재정리 될 수 있다. 그리고 이 변수 뒤에 존재하는 다른 명령들 또한 자기들끼리 재정리 될 수 있다. 다만, volatile 변수에 대한 명령 이전/이후에 존재한다는 그 전제는 반드시 지켜진다.
만약 재정리가 된다면, 변수의 가시성에 손상을 줄 수 있다.
public void put(Object newObject) {
while(hasNewObject) {
//wait - do not overwrite existing new object
}
object = newObject;
hasNewObject = true; //volatile write
}위 put()의 실행 코드가 다음과 같이 재정리 될 수 있다고 가정해보자.
while(hasNewObject) {
//wait - do not overwrite existing new object
}
hasNewObject = true; //volatile write
object = newObject;volatile 변수 hasNewObject 로의 쓰기 작업이 object 가 세팅되기 전으로 바뀌었다. JVM 의 시각으로 이것은 완전히 유효한 코드이다. 두 쓰기 작업은 서로에게 의존하지 않는다.
그러나 이 재정리는 object 변수의 가시성에 손상을 줄 수 있다. 먼저, Thread B 는 Thread A 가 실제로 object 에 newObject 를 세팅하기도 전에 hasNewObject 값을 true 로 읽을 수가 있다. 둘째로, 새 객체가 세팅된 object 변수가 어느 시점에 메인 메모리로 저장될지에 대한 보장이 없다.
정리
volatile 변수의 읽기/쓰기는 메인 메모리를 이용한다. 메인 메모리로부터 데이터를 읽고 쓰는 작업은 CPU 캐시를 이용하는 것 보다 많은 비용이 요구된다. 또한 volatile 선언은 JVM 의 성능 향상을 위한 기술인, 코드 재정리를 막기도 한다. 그러므로 volatile 키워드는 변수의 가시성 보장이 반드시 필요한 경우에만 사용되어야 한다.
출처 :
'Java' 카테고리의 다른 글
| [Java] PriorityQueue(우선순위 큐) (0) | 2021.01.28 |
|---|---|
| [Java] ThreadLocal (0) | 2021.01.24 |
| [Java] 객체 지향 설계 5원칙 - SOLID (0) | 2021.01.22 |
| [Java] ArrayList는 어떻게 동적으로 사이즈가 늘어나는가? add() flow(동작 방식) (0) | 2021.01.19 |
| [Java] ArrayList 깊은 복사, 얕은 복사 (3) | 2021.01.19 |



