
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- JPA
- IntellJ
- Collection
- 스프링
- 토비의 스프링
- 쿠버네티스
- Java
- mysql
- SpringBoot
- 스트림
- GC
- Real MySQL
- gradle
- Stack
- 백준
- 보조스트림
- Stream
- list
- thread
- OS
- Kotlin
- MSA
- 자바 ORM 표준 JPA 프로그래밍
- jvm
- K8s
- 자바
- 토비의 스프링 정리
- spring
- 이스티오
- redis
- Today
- Total
인생을 코딩하다.
[JPA] 2차 캐시 본문

안녕하세요. 오늘은 2차 캐시에 관해 정리한 내용을 작성해 보도록 하겠습니다.
그리고 2차 캐시에 관해 글을 작성하기에 앞서 우선 캐시와 JPA의 1차 캐시에 관해 잠시 설명해 보도록 하겠습니다.
🔍 캐시란 무엇이고, 캐시는 왜 사용하는 걸까요?
Cache는 간단히 말해서 나중의 요청에 대한 결과를 미리 저장했다가 빠르게 사용하는 것입니다.
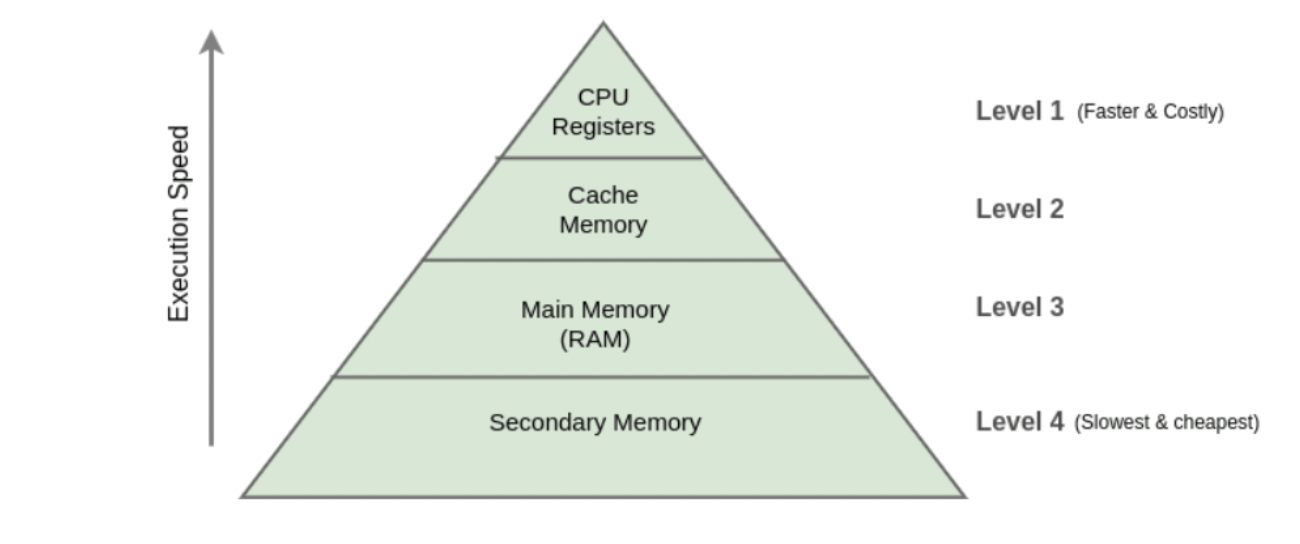
위로 갈수록 빠르고 비싸고 밑으로 갈수록 느리고 저렴한 저장소라고 생각하면 됩니다. Secondary Memory를 디스크 영역이라고 보시면 됩니다.
기본적으로 데이터는 컴퓨터가 꺼져도 저장이되어야 하기 떄문에 Secondary Memory(SSD,HDD 등)에 저장이 되는데, 기술이 발달하고 하드웨어들이 커지다보니깐 Main Memory나 Cache Memory, CPU Registers 등에 저장하여 더 빠르고 쉽게 접근할 수 있도록 하는 여러 방법들이 생겼습니다.
그리고 캐시를 사용하면 관계형 데이터베이스(MySQL등)에 접근하는 것보다 훨씬 빠른데 그 이유는 위의 그림처럼 메모리 접근이 디스크 접근보다 빠르기 때문입니다.
즉, Database보다 더 빠른 Memory에 더 자주 접근하고 덜 자주 바뀌는 데이터를 저장할때 적합합니다.
🔍 1차 캐시는 무엇일까요?
네트워크를 통해 데이터베이스에 접근하는 시간 비용은 애플리케이션 서버에서 내부 메모리에 접근하는 시간 비용보다 수만에서 수십만 배 이상 비쌉니다. 따라서 조회한 데이터를 메모리에 캐시해서 데이터베이스 접근 횟수를 줄이면 애플리케이션 성능을 획기적으로 개선할 수 있습니다.
- 일반적인 웹 애플리케이션 환경은 트랜잭션이 시작하고 종료할 때 까지만 1차 캐시가 유효합니다.
- OSIV를 사용해도 클라이언트의 요청이 들어올 때부터 끝날때 까지만 1차 캐시가 유효합니다.
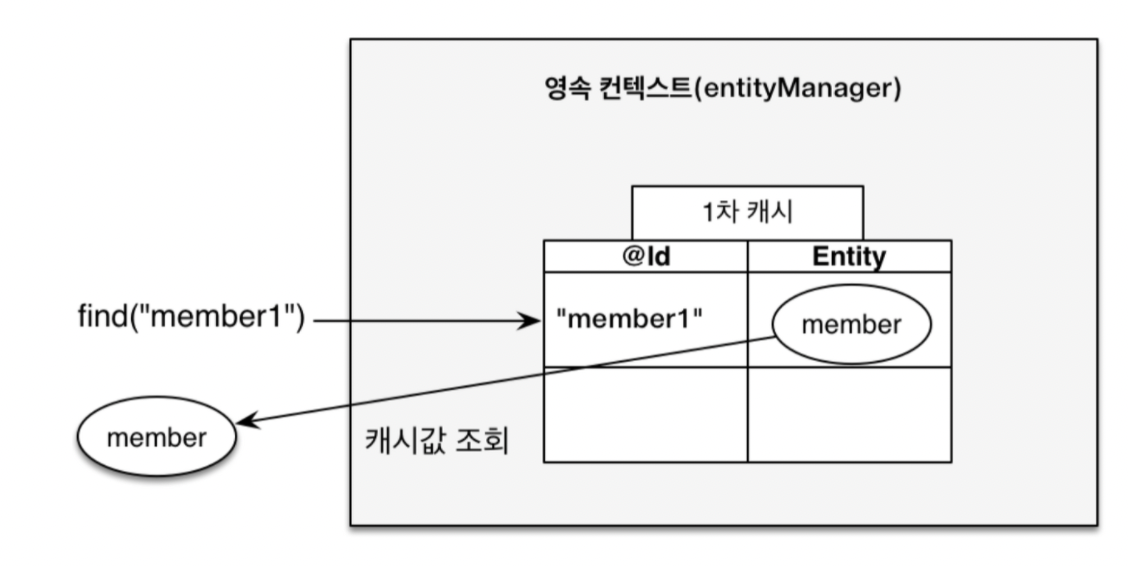
영속성 컨텍스트 내부에는 엔티티를 보관하는 저장소가 있는데, 이를 1차 캐시라고 합니다.
- 1차 캐시는 영속성 컨텍스트 내부에 있습니다. 엔티니 매니저로 조회하거나 변경하는 모든 엔티티는 1차 캐시에 저장됩니다..
- 1차 캐시는 끄고 켤 수 있는 옵션이 아닙니다. 영속성 컨텍스트 자체가 사실상 1차 캐시라고 할 수 있습니다.
1차 캐시의 동작 방식은 아래와 같습니다.
- 최초 조회할 때는 1차 캐시에 엔티티가 없습니다.
- 데이터베이스에서 엔티티를 조회합니다.
- 엔티티를 1차 캐시에 보관합니다.
- 1차 캐시에 보관된 결과를 반환합니다.
- 이후 같은 엔티티를 조회하면 1차 캐시에 같은 엔티티가 있으므로 데이터베이스를 조회하지 않고 1차 캐시의 엔티티를 그대로 반환합니다.
- 1차 캐시는 객체의 동일성을 (a == b)를 보장합니다.
1차 캐시나 영속성에 관해 더 구체적인 내용은 여기를 참고하시면 될 것 같습니다.
🔍 2차 캐시는 무엇일까요?
애플리케이션에서 공유하는 캐시를 JPA는 공유 캐시(Shared Cache)라 하는데 일반적으로 2차 캐시 (Second Level Cache, L2 Cache)라 부릅니다. 2차 캐시는 애플리케이션 범위의 캐시입니다. 따라서 애플리케이션을 종료할 때까지 캐시가 유지됩니다. 분산 캐시나 클러스터링 환경의 캐시는 애플리케이션보다 더 오래 유지 될 수도 있습니다.
엔티티 매니저를 통해 데이터를 조회할 때 우선 2차 캐시에서 찾고 없으면 데이터베이스에서 찾습니다. 2차 캐시를 적절히 활용하면 데이터베이스 조회 횟수를 획기적으로 줄일 수 있습니다.
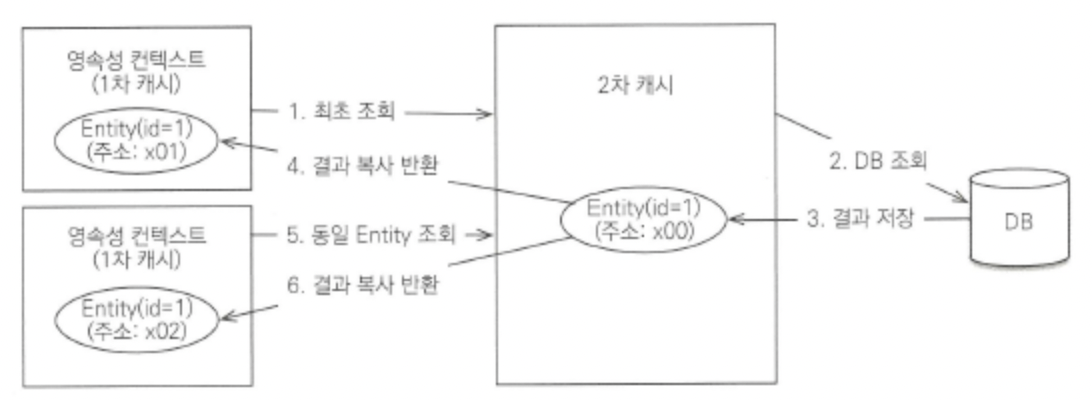
하이버네이트를 포함한 대부분의 JPA 구현체들은 애플리케이셔 범위의 캐시를 지원하는데 이것을 2차 캐시라고 합니다.
2차 캐시의 동작 방식은 아래와 같이 동작합니다.
- 영속성 컨텍스트는 엔티티가 필요하면 2차 캐시를 조회합니다.
- 2차 캐시에 엔티티가 없으면 데이터베이스를 조회합니다.
- 결과를 2차 캐시에 보관합니다.
- 2차 캐시는 자신이 보관하고 있는 엔티티를 복사해서 반환합니다.
- 2차 캐시에 저장되어 있는 엔티티를 조회하면 복사본을 만들어 반환합니다.
- 2차 캐시는 데이터베이스 기본 키를 기준으로 캐시하지만 영속성 컨텍스트가 다르면 객체 동일성 (a == b)을 보장하지 않습니다.
정리하자면, 2차 캐시는 동시성을 극대화하기 위해 캐시한 객체를 직접 반환하지 않고 복사본을 만들어서 반환합니다.
🔍 2차 캐시는 왜 필요할까요? 1차 캐시와 어떤 차이점이 존재할까요?

위 그림은 2차 캐시 적용 전의 그림이고, 아래 그림은 2차 캐시를 적용한 후의 그림입니다.

2차 캐시는 동시성을 극대화하기 위해 캐시 한 객체를 직접 반환하지 않고 복사본을 만들어서 반환합니다. 여기서 복사본을 반환하는 이유는 캐시한 객체를 그대로 반환하면 여러 곳에서 같은 객체를 동시에 수정하는 문제가 발생할 수 있습니다.
동시성은 싱글 코어에서 멀티 스레드를 동작시키기 위한 방식으로 멀티 태스킹을 위해 여러 개의 스레드가 번갈아가면서 실행되는 성질을 말합니다. 동시성을 이용한 싱글 코어의 멀티 태스킹은 각 스레드들이 병렬적으로 실행되는 것처럼 보이지만 사실은 번갈아가면서 조금씩 실행되고 있는 것입니다.
그렇다고 이것을 해결하기 위해서 객체에 락을 걸면 성능 및 동시성이 떨어질 수 있습니다. 그래서 2차 캐시는 원본 대신 복사본을 반환합니다. 2차 캐시를 잘만 사용하면 1차 캐시의 동시성 문제를 해결하고 애플리케이션의 조회 성능을 끌어올릴 수 있습니다.
🔍 2차 캐시는 어떻게 사용할까요?
캐시 모드를 설정하려면 Entity 객체 위에 @Cacheable을 작성해줍니다. 그리고 application.yml에 아래와 같이 설정을 해주어야 합니다.
spring.jpa.properties.hibernate.cache.use_second_level_cache = true
// 2차 캐시 활성화합니다.
spring.jpa.properties.hibernate.cache.region.factory_class
// 2차 캐시를 처리할 클래스를 지정합니다.
spring.jpa.properties.hibernate.generate_statistics = true
// 하이버네이트가 여러 통계정보를 출력하게 해주는데 캐시 적용 여부를 확인할 수 있습니다.@Entity // 2차캐시 활성화. true는 기본 값이라 생략가능 @Cacheable(value=true)
@Cacheable
public class Team {
@Id @GeneratedValue
private Long id;
...
}@Cacheable을 안붙이고 사용가능하게도 바꿔줄 수 있습니다.
spring.jpa.properties.javax.persistence.sharedCache.mode= (기본값) Enable_selectivecache mode는 아래와 같이 5가지가 있습니다.
| 캐시 모드 | 설명 |
| ALL | 모든 엔티티를 캐시합니다. |
| NONE | 캐시를 사용하지 않습니다. |
| ENABLE_SELECTIVE | Cacheable(true)로 설정된 엔티티만 캐시를 적용합니다. |
| DISABLE_SELECTIVE | 모든 엔티티를 캐시하는데 Cacheable(false)만 캐시하지 습니다. |
| UNSPECIFIED | JPA 구현체가 정의한 설정을 따릅니다. |
위의 @Cacheable 외에도 @Cache라는 어노테이션이 존재합니다. 하이버네이트 전용입니다.
@Cacheable
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
@Entity
public class Academy {
@Id
@GeneratedValue
private Long id;
private String name;
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
@OneToMany(cascade = CascadeType.ALL)
@JoinColumn(name="academy_id")
private Set<Subject> subjects = new LinkedHashSet<>();
...
}@Cacheable의 속성 전략
- usage : CacheConcurrencyStrategy를 사용해서 캐시 동시성 전략을 설정합니다.
- region : 캐시 지역을 설정합니다.
- include : 연관 객체를 캐시에 포함할지 선택합니다. all, non-lazy 옵션을 선택할 수 있습니다. 기본값은 all 입니다.
캐싱 동시성 전략 (CacheConcurrencyStrategy)
- READ_ONLY : 자주 조회하고 수정 작업을 하지 않는 데이터에 적합합니다.
- READ_WRITE : 조회 및 수정 작업을 하는 데이터에 적합합니다. Phantom Read 가 발생할 수 있으므로 SERIALIZABLE 격리 수준에서는 사용할 수 없습니다.
- NONSTRICT_READ_WRITE : 거의 수정 작업을 하지 않는 데이터에 적합합니다.
긴 글 읽어주셔서 감사합니다. 잘못된 내용이 있으면 피드백 부탁드리겠습니다.
참고하면 도움이 될만한 글 :
- https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#reference
- https://docs.jboss.org/hibernate/orm/5.4/userguide/html_single/Hibernate_User_Guide.html
- https://happyer16.tistory.com/entry/16%EC%9E%A5-%ED%8A%B8%EB%9E%9C%EC%9E%AD%EC%85%98%EA%B3%BC-%EB%9D%BD-2%EC%B0%A8-%EC%BA%90%EC%8B%9C
- https://incheol-jung.gitbook.io/docs/study/jpa/16
- https://jiwondev.tistory.com/242
- https://www.whiteship.me/-ed-95-98-ec-9d-b4-eb-b2-84-eb-84-a4-ec-9d-b4-ed-8a-b8-2-ec-b0-a8--ec-ba-90-ec-8b-b1--ec-a0-81-ec-9a-a9-ed-95-98-ea-b8-b0/
'JPA' 카테고리의 다른 글
| [자바 ORM 표준 JPA 프로그래밍 정리] , 7장 고급 매핑 (0) | 2021.04.25 |
|---|---|
| [자바 ORM 표준 JPA 프로그래밍 정리], 6장 다양한 연관관계 매핑 (0) | 2021.04.25 |
| [자바 ORM 표준 JPA 프로그래밍 정리], 5장 연관관계 매핑 기초 (0) | 2021.04.25 |
| [자바 ORM 표준 JPA 프로그래밍 정리], 4장 엔티티 매핑 (0) | 2021.04.25 |
| [자바 ORM 표준 JPA 프로그래밍 정리], 3장 영속성 관리 (2) | 2021.04.25 |



